La détection des textes générés par l’IA, une bataille perdue d’avance ?
Plus de trois ans après l’émergence de ChatGPT, il n’est toujours pas possible de déterminer avec certitude si un contenu a été généré par une IA. Entre attentisme des acteurs et limites techniques, le dossier s’enlise.


Il aura fallu du temps, mais OpenAI sait désormais reconnaître les images générées par ses modèles. En mai dernier, la firme a déployé publiquement un outil en ligne capable de détecter si un visuel a été créé à l’aide de ChatGPT ou de son API, en croisant les métadonnées C2PA et le filigrane invisible SynthID développé par Google DeepMind.
Une avancée qui se sera fait désirer, et qui ramène dans son sillage une question récurrente : pourquoi, plus de trois ans après l’émergence de ChatGPT, la détection des textes générés par IA patine-t-elle encore ? Et, aussi, pourra-t-on un jour distinguer un texte produit par un robot de celui rédigé par un humain, alors que certaines études, peut-être alarmistes, estiment que plus de la moitié des articles publiés sur le web sont désormais synthétiques ?
Les tentatives avortées d’OpenAI
Naturellement scrutée dans ce dossier en raison de son statut de pionnier, la société créatrice de ChatGPT était passée proche de transformer l’essai, il y a de cela plusieurs mois. En août 2024, le Wall Street Journal révélait qu’OpenAI disposait, depuis environ un an, d’un système de watermarking textuel, « invisible à l’œil nu », permettant de déterminer avec certitude si l’intégralité ou une partie d’un texte avait été générée à l’aide de ses grands modèles de langage. Un outil « anti-triche » qui, selon les documents internes consultés par le média américain, affichait un taux de réussite de 99,9 %. Son principe ? Remanier légèrement la manière dont l’agent conversationnel compose ses phrases, afin de créer un pattern imperceptible à la lecture, mais pouvant être détecté par un algorithme.
Très prometteur sur le papier, l’outil ne sera jamais déployé à grande échelle. « En tentant de décider de la marche à suivre, les employés d’OpenAI ont été tiraillés entre l’engagement pris en faveur de la transparence et le désir d’attirer et de retenir les utilisateurs », écrivait le Wall Street Journal. Certains s’inquiétaient des techniques de contournement, d’autres redoutaient un impact sur la qualité des outputs. Une étude menée auprès des utilisateurs, en 2023, a également pesé dans la balance : plus de 30 % des sondés déclaraient qu’ils utiliseraient moins ChatGPT si une telle technologie était déployée, et 69 % craignaient qu’elle mène à de fausses accusations de tricherie.
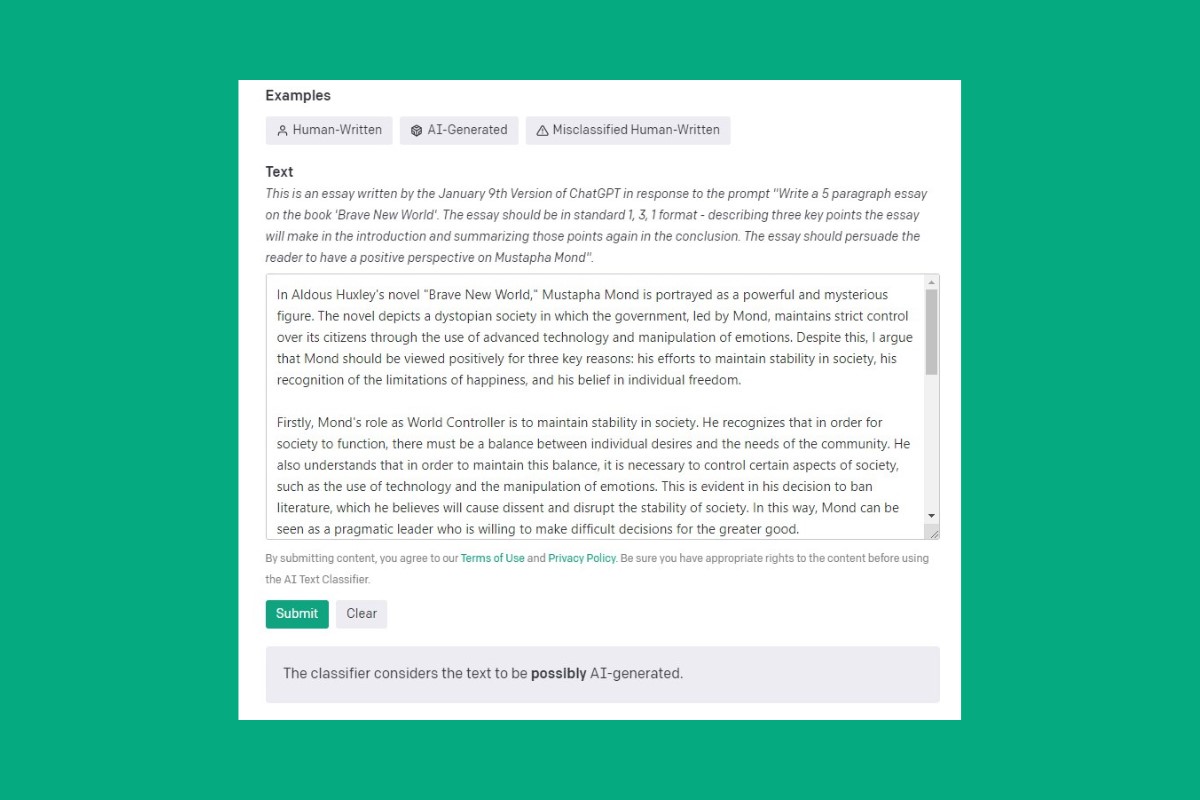
Il ne s’agissait pas de la première tentative avortée d’OpenAI sur le terrain de la détection. En janvier 2023, la firme californienne, alors en plein boom, avait lancé un outil gratuit baptisé AI Text Classifier, qui attribuait à chaque texte analysé un degré de probabilité d’avoir été généré par une intelligence artificielle, de « very unlikely » à « likely AI-generated ». Limité dès le départ, entraîné sur des contenus anglophones et ne pouvant être exploité que pour des textes incluant plus de 1 000 caractères, l’outil, raillé par de nombreux médias, est finalement débranché six mois plus tard. « Il identifiait correctement 26 % des textes générés par IA comme probablement rédigés par une IA, tout en classant à tort 9 % des textes humains dans cette même catégorie », reconnaissait la firme dans un blog post.
Un filigrane universel qui ne l’est pas encore
Ces dernières années, Google a également investi ce terrain. Depuis 2023, la firme développe SynthID, un filigrane invisible initialement dédié aux images générées par ses modèles, et progressivement étendu aux contenus textuels, audio et vidéo créés par ses modèles, de Gemini à Lyria en passant par Veo.
Lors de la conférence Google I/O 2025, la firme de Mountain View avait même franchi un cap en dévoilant SynthID Detector, un portail permettant de scanner ces différents types de contenus pour y détecter la présence du filigrane. Problème : si la technologie a été rendue open source, le portail n’a jamais été déployé publiquement et ne reste accessible, pour l’heure, qu’aux journalistes, chercheurs et professionnels passés par une liste d’attente. Surtout, à l’instar des outils d’OpenAI, SynthID ne détecte que les contenus générés par ses modèles. Un texte créé par ChatGPT, Le Chat ou Claude, n’ayant pas a été marqué par SynthID, passera entre les mailles du filet. « Cela contraint les utilisateurs à jongler entre plusieurs outils pour vérifier l’origine d’un contenu. Malgré les appels des chercheurs en faveur d’un système unifié, et les tentatives de grands acteurs comme Google pour faire adopter leur standard par d’autres, le paysage reste fragmenté », déplore T.J. Thomson, professeur associé de communication visuelle à l’Université RMIT de Melbourne, dans un article publié sur The Conversation.
Un marché né dans l’urgence
L’attentisme des acteurs de l’IA sur le terrain de la détection a, en tout cas, eu le mérite d’ouvrir un marché. Dès janvier 2023, soit quelques mois après le lancement de ChatGPT, plusieurs outils ont émergé pour tenter de combler le vide, parmi lesquels GPTZero, Originality AI ou Winston sur le marché anglophone, et Lucide AI, Draft & Goal ou Compilatio sur le marché francophone. L’exemple de GPTZero illustre plutôt bien l’ampleur d’un besoin qui s’est manifesté presque instantanément. Mis en ligne le 2 janvier 2023 par Edward Tian, alors étudiant à Princeton, et brièvement annoncé sur Twitter, l’outil avait attiré plusieurs milliers de visiteurs dès le premier jour, au point de saturer le serveur, apprenait-on dans les colonnes de WIRED. L’engouement n’a ensuite pas faibli : douze mois plus tard, GPTZero comptait 4 millions d’utilisateurs, et sa société créatrice était déjà rentable, rapportait TechCrunch.
Si chacune de ces solutions a conçu sa propre recette pour tenter de repérer les contenus synthétiques, elles traquent toutes des indices similaires : la ponctuation, la structure des phrases, mais aussi la fréquence de certains mots ou expressions. Elles disposent aussi de leurs propres spécificités. Pour Lucide AI, un outil de détection francophone lancé en 2024, une attention particulière est, par exemple, portée aux « grappes de mots ». « Les humains écrivent avec plus de grappes de mots que les IA », explique Arthur Villecourt, cofondateur de la solution, désignant par là ces groupes de termes qu’un auteur humain associe spontanément par proximité sémantique ou habitude stylistique. « Ça crée des variations naturelles, alors qu’un modèle a tendance à produire des textes avec une structure plus régulière. »
« Ces facteurs représentent peut-être 20 ou 25 % de l’analyse », tempère Arthur Villecourt, pour qui s’appuyer uniquement sur ces signaux est loin d’être suffisant pour produire une détection fiable. Pour attribuer un score de probabilité crédible, Lucide AI a donc développé son propre algorithme, branché à un LLM et entraîné en permanence sur des contenus journalistiques, universitaires et sur des textes générés par IA. Cette « brique supplémentaire » est, selon lui, ce qui sépare les solutions payantes sérieuses des détecteurs gratuits, qui se contentent souvent d’analyser la ponctuation ou la fréquence des mots. « Le système via LLM est plus coûteux, mais aussi plus chiadé », ajoute-t-il. Autre avantage de l’approche : entraîné en continu sur des contenus textuels, l’algorithme s’adapte plus facilement aux avancées des modèles.
Les signaux traqués par Lucide AI pour détecter un texte généré par IA
Pour attribuer un score, l’entreprise française analyse plusieurs signaux, qu’elle croise ensuite avec son propre LLM :
- La perplexité : elle mesure la probabilité qu’un mot suive le précédent. Plus elle est faible, plus le texte est fluide et régulier, ce qui caractérise les productions d’un modèle d’IA.
- Les grappes de mots : un humain regroupe naturellement certains termes par proximité sémantique. Les modèles d’IA tendent à les distribuer de façon plus uniforme.
- La fréquence : les modèles d’IA ont tendance à surutiliser certains termes ou structures syntaxiques, alors que l’écriture humaine est plus variée.
- La ponctuation : les modèles produisent des schémas de ponctuation trop cohérents ou, à l’inverse, présentant des erreurs subtiles.
Un indicateur, jamais une certitude
Aucune de ces solutions ne revendique pour autant une fiabilité absolue. Un contenu SEO bas de gamme produit avant l’ère de l’IA ou une écriture scolaire peu variée peuvent déclencher une alerte. « Des faux positifs, ça existe sur tous les détecteurs. C’est ce qui rend le marché particulier », admet Arthur Villecourt.
Est-ce que la détection d’IA sera un jour une science fiable ? Non, je ne pense pas.
Les techniques de contournement, désormais bien documentées, compliquent aussi l’analyse. Chez Lucide AI, un score inférieur à 25 % est considéré comme particulièrement suspect. Au-delà de 75 %, le texte a probablement été rédigé par un humain, mais rien n’exclut qu’il se soit discrètement appuyé sur l’IA. En se créant, par exemple, un persona pour que le modèle épouse son style d’écriture, ou en repassant le texte généré dans un outil d’humanisation, comme QuillBot, capable de briser certains patterns. « Ça ne peut jamais être une réponse parfaite. Ça peut être un indicateur, mais ça ne sera jamais plus qu’un indicateur. »
Le web indexe et valorise sans distinguer l’homme de la machine
Mais alors, est-on condamné au doute permanent à chaque fois qu’on lit un contenu sur le web ? Pas forcément, mais il reste encore du chemin. Selon lui, même si le watermarking textuel représente une piste viable, rien ne devrait évoluer de sitôt : le marché de la détection reste « trop petit » pour intéresser les grands acteurs, qui n’ont de toute façon aucune raison commerciale de s’y engager. « Google, par exemple, ça fait ses affaires qu’on utilise son LLM et qu’on dépense de l’argent pour générer du texte. Je ne suis pas catégorique, mais j’ai du mal à cerner l’intérêt, pour eux, d’aller signaler l’utilisation de leur propre outil », resitue Arthur Villecourt.
Au-delà des intérêts commerciaux, la question de la provenance semble davantage préoccuper les humains que les algorithmes. « Le seul truc qui compte, pour les algorithmes, c’est comment les humains réagissent au contenu. Qu’il soit généré ou pas, finalement, ils s’en fichent », abonde-t-il. Une étude menée par Ahrefs, datant de juillet 2025, tend à lui donner raison : la plupart des pages les mieux classées sur Google auraient été rédigées à l’aide de l’IA.


Nous avons besoin de vous !
Nous réalisons une courte enquête pour comprendre vos besoins et mieux y répondre sur BDM.
Je donne mon avisLes meilleurs détecteurs de texte par IA
Compilatio Magister+
Originality.ai
Winston AI





