Top 20 des modèles d’IA les plus performants en novembre 2025 : le classement complet
Dévoilé la semaine dernière, Gemini 3 Pro prend la première place du classement établi par LMArena. OpenAI, xAI et Anthropic doivent se contenter des places d’honneur.

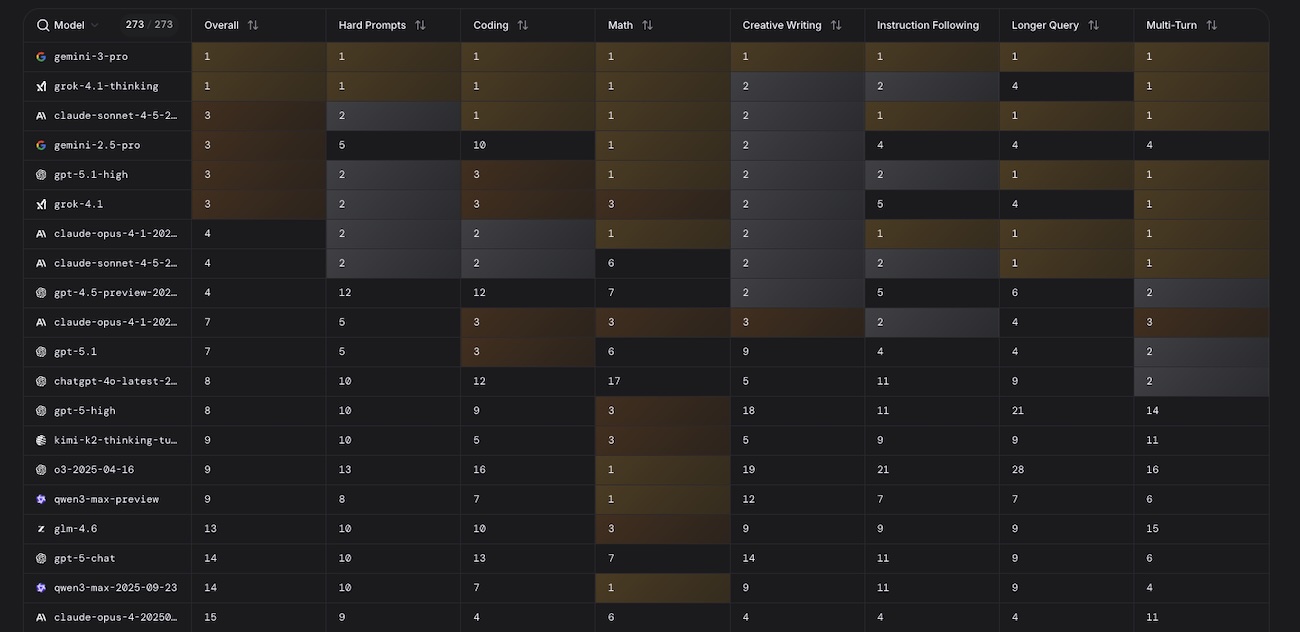
Comme Google s’en félicitait dans son billet de présentation, Gemini 3 Pro, déployé dans l’application Gemini depuis ce mardi 18 novembre 2025, domine assez outrageusement la LMArena, un classement qui évalue objectivement les performances des modèles d’IA disponibles sur le marché. À ce stade, il surpasse ses concurrents en écriture créative, en codage, en raisonnement mathématique et en adhérence au prompt.
Les 10 modèles d’IA les plus performants en novembre 2025
La firme de Mountain View, qui conserve par ailleurs la quatrième position du classement général grâce à Gemini 2.5 Pro, n’est pas le seul acteur à avoir franchi un cap technologique ces derniers jours. Dévoilé le 17 novembre 2025, le modèle Grok 4.1, dépeint par xAI comme « performant dans les interactions créatives, émotionnelles et collaboratives » et moins enclin aux hallucinations, s’invite lui aussi dans les premières positions du classement LMArena. Sa version « thinking », la plus avancée, occupe la deuxième place, tandis que la version standard se hisse au sixième rang.
La dynamique est en revanche moins favorable à Anthropic : la version « thinking » de Claude 4.5 Sonnet, en tête le mois dernier, recule de deux places. La société créatrice de Claude conserve toutefois quatre modèles dans le top 10, soit deux fois plus que chacun de ses concurrents directs.
Et OpenAI, dans tout ça ? L’entreprise a, semble-t-il, corrigé certains défauts de son modèle étendard, puisque la version « high » de GPT-5.1 se classe cinquième — un gain de trois places par rapport à GPT-5 le mois dernier. En revanche, GPT-4.5 Preview recule de cinq positions, et GPT-4o, toujours accessible dans ChatGPT, quitte enfin la première partie de tableau.
Voici les dix modèles les plus performants du marché, toutes tâches confondues, en novembre 2025 :
- Gemini 3 Pro
- Grok 4.1 « thinking »
- Claude Sonnet 4.5 « thinking »
- Gemini 2.5 Pro
- GPT-5.1 « high »
- Grok 4.1
- Claude Opus 4.1 « thinking »
- Claude Sonnet 4.5
- GPT-4.5 Preview
- Claude Opus 4.1
Les modèles d’IA les plus performants par catégorie
Au-delà de son classement général, LMArena propose aussi des leaderboards par catégorie, afin d’évaluer plus précisément les forces et les faiblesses de chaque modèle selon les tâches. Voici les modèles les plus performants par domaine en novembre 2025 :
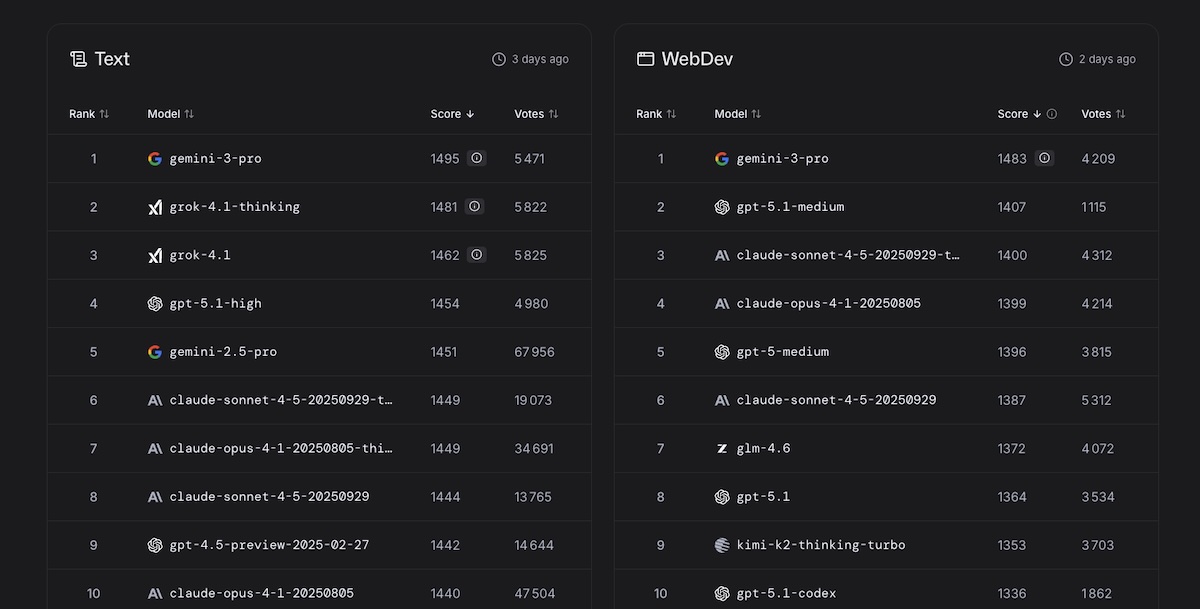
- Génération de texte : Gemini 3 Pro prend la relève de son prédécesseur et occupe la première position, devant deux versions de Grok. GPT-5.1 doit se contenter de la quatrième place.
- Développement web : le « modèle le plus intelligent à ce jour » de Google ravit à OpenAI la seule première position qu’elle occupait encore le mois dernier. Claude Sonnet 4.5 complète le podium.
- Génération d’images : Gemini 3 Pro Image Preview, également connu sous le nom Nano Banana Pro et déployé ce jeudi, s’empare de la première place. Il devance Hunyuan Image 3.0, un modèle chinois. À noter que Google est l’acteur le plus représenté dans cette catégorie.
- Recherche web : voici un domaine où Gemini 3 Pro n’excelle pas encore, puisqu’il n’apparaît même pas dans le top 10, au contraire de Gemini 2.5 Pro, troisième. Grok 4 occupe la première position, devant Sonar, le modèle de recherche documentaire de Perplexity.
Comment les modèles d’IA sont-ils classés par LMArena ?
Pour proposer une vue neutre et représentative du marché de l’IA, LMArena fait appel à ses utilisateurs. Sur sa plateforme, la structure indépendante organise des duels anonymes entre les modèles : chacun reçoit le même prompt, produit une réponse, et les utilisateurs désignent celle qui paraît la plus pertinente. Chaque modèle obtient un score Elo, une cote qui évolue après chaque confrontation. Une victoire contre un adversaire mieux classé rapporte davantage de points, tandis qu’une défaite face à un modèle plus faible en fait perdre.


La boîte à questions sur l'IA générative
Outils, prompts, usages professionnels, comparatifs... Posez toutes vos questions à Ludovic Salenne, expert IA !
Je pose une questionLes meilleurs outils Visibilité LLM
ActivGEO by Semactic
Brand Score AI

Meteoria





