Pourquoi l’IA gagne aux Olympiades de maths mais ne sait pas lire l’heure
Une IA peut gagner une médaille d’or aux Olympiades de mathématiques, puis se tromper de plusieurs heures en lisant une horloge. Le rapport AI Index 2026 de Stanford documente ce paradoxe que les chercheurs nomment « jagged intelligence ».

Sur les benchmarks conçus pour défier l’intelligence humaine, les modèles d’IA enchaînent les records, jusqu’aux médailles d’or aux Olympiades internationales de mathématiques. Mais sur des actions du quotidien, ils peuvent encore se tromper de plusieurs heures sur l’heure qu’il est ou rater 9 tâches ménagères sur 10. Le rapport AI Index 2026 de Stanford documente ce paradoxe et le nomme : la « jagged intelligence ».
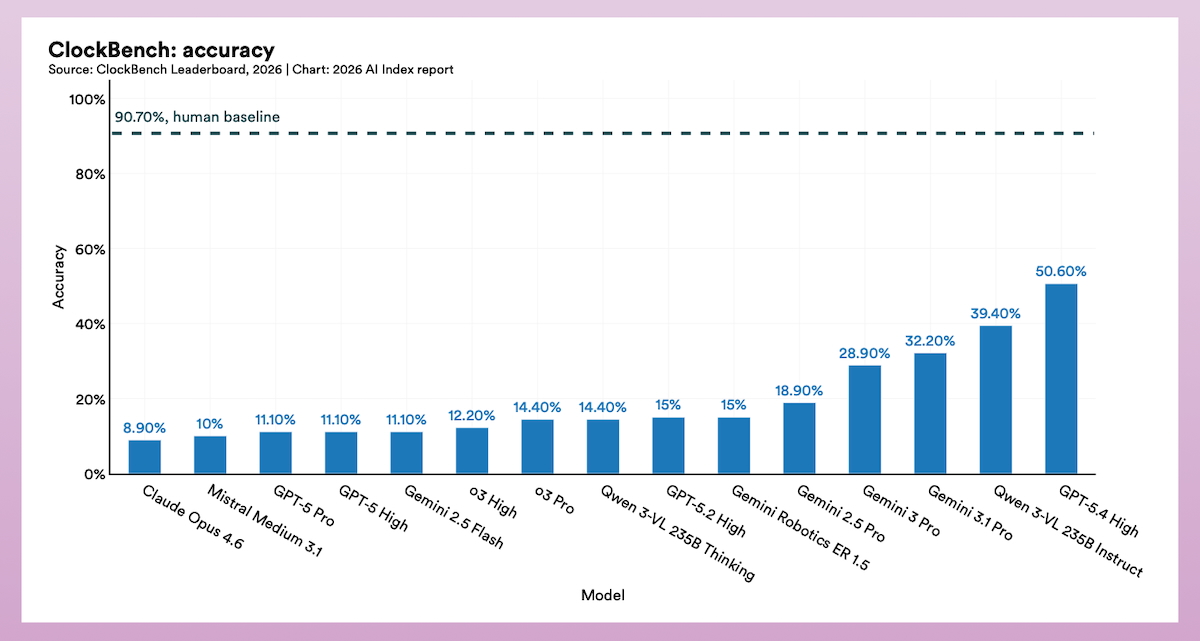
Une médaille d’or aux Olympiades, 50,6 % à la lecture d’une horloge
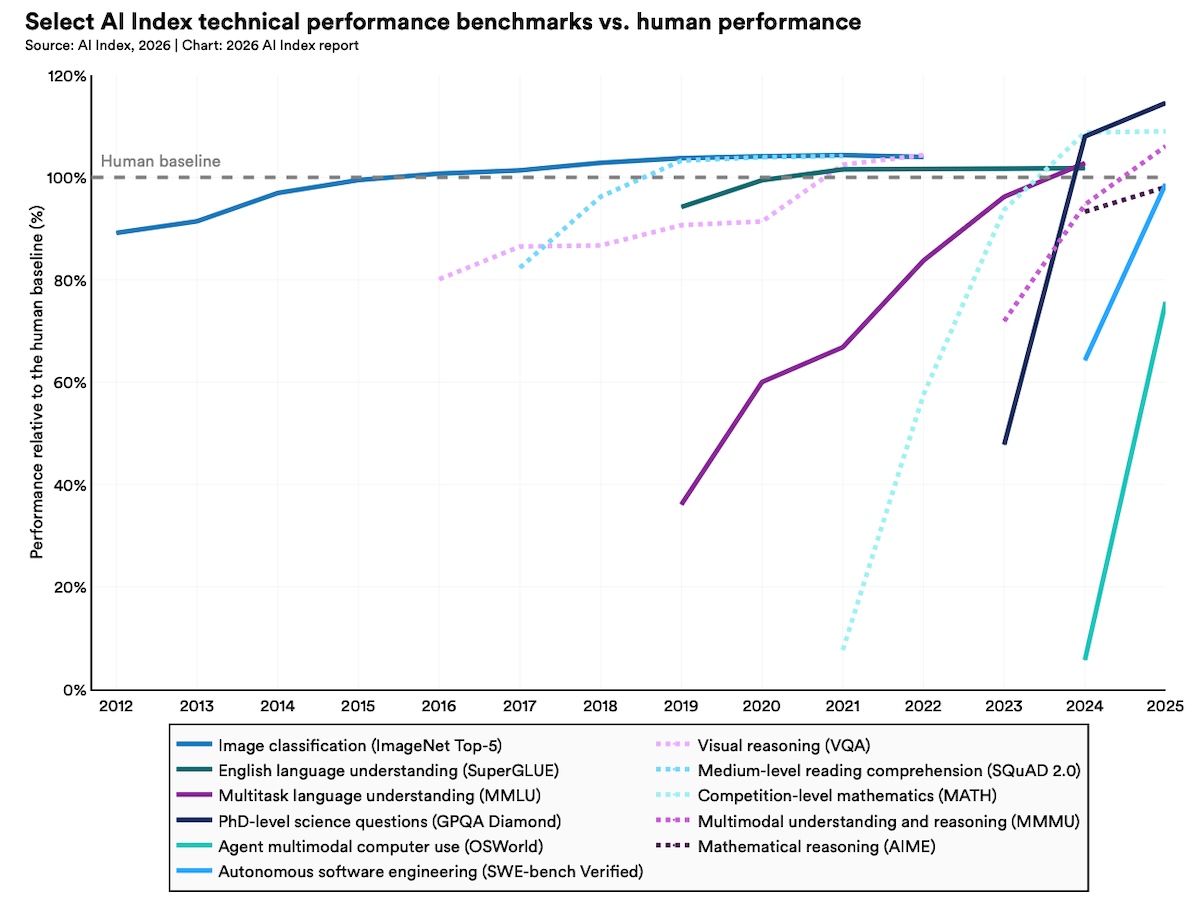
Publié le 13 avril 2026 dans sa neuvième édition, le rapport AI Index 2026 de Stanford HAI consacre une section à ce que les chercheurs et chercheuses appellent la « jagged intelligence ». Le terme désigne le fait qu’un même modèle peut atteindre des performances surhumaines sur certaines tâches d’élite et échouer sur des actions plus basiques. Le constat complète celui dressé quant à la crise de crédibilité des benchmarks : aux problèmes de mesure s’ajoute une réalité que ces mêmes mesures peinent à capturer, celle d’une frontière de capacités très inégalement répartie.
Les exemples du sommet sont nombreux. En mathématiques, Gemini Deep Think de Google a remporté la médaille d’or à l’Olympiade internationale 2025 en résolvant cinq problèmes sur six, entièrement en langage naturel et dans les 4 heures 30 imparties. C’est un bond notable depuis 2024, où la médaille d’argent obtenue avait nécessité de traduire les problèmes dans un langage formel et plusieurs jours de calcul.
Sur ClockBench en revanche, un test conçu pour évaluer la lecture d’horloges analogiques (180 designs, 720 questions), le meilleur modèle (GPT-5.4 High) plafonne à 50,6 % de réussite, contre 90,1 % chez les humains (voir image de une). L’écart est encore plus parlant dans la nature des erreurs : quand les modèles se trompent, leur erreur médiane atteint 1 à 3 heures, contre 3 minutes seulement pour un humain.
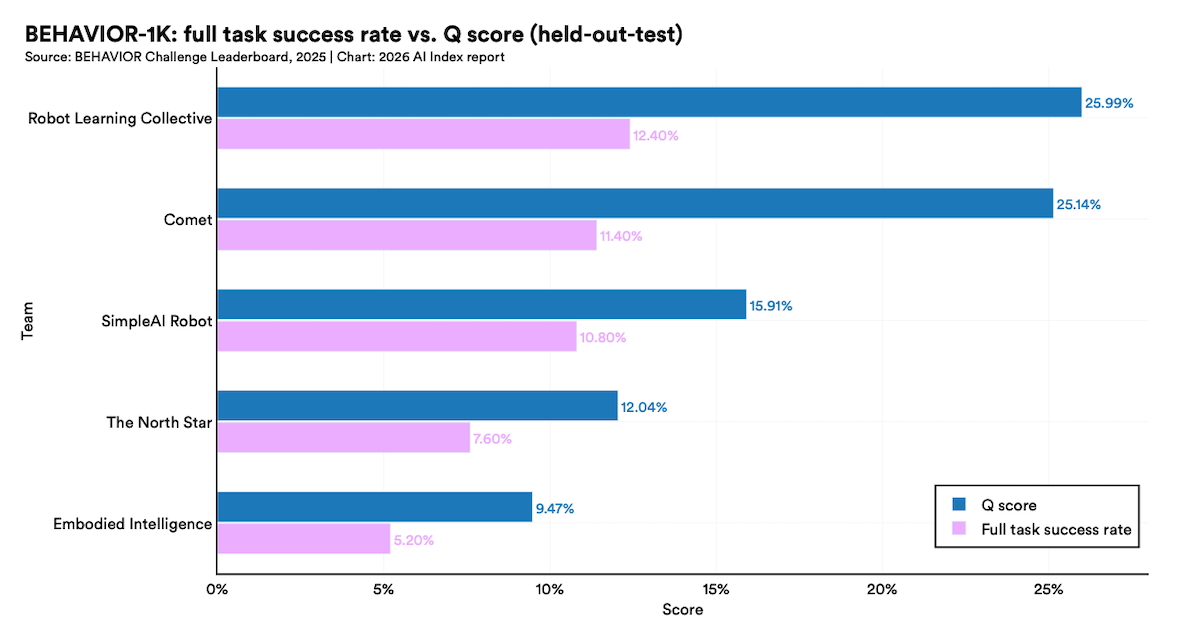
L’asymétrie se retrouve sur d’autres terrains. Côté robotique, les meilleurs systèmes atteignent 89,4 % de réussite sur RLBench en simulation, mais l’équipe gagnante du BEHAVIOR Challenge 2025 (Robot Learning Collective), qui évalue 1 000 tâches ménagères réalistes, ne complète intégralement que 12,4 % des tâches. Pour les sciences, plusieurs modèles dépassent en moyenne les chimistes humains sur ChemBench, mais tombent à moins de 20 % sur la réplication d’astrophysique et à 33 % sur les questions d’observation de la Terre.
Exécuter de manière fiable des tâches ménagères en environnement réaliste reste hors d’atteinte des capacités actuelles.
Pourquoi cette frontière reste en dents de scie
L’origine de ces échecs ne tient pas seulement aux données d’entraînement. Une étude publiée en 2025 dans IEEE Internet Computing., citée par le rapport, a tenté de corriger la performance des modèles sur les horloges en les entraînant sur 5 000 images synthétiques. Les modèles se sont améliorés sur les horloges familières, mais ont échoué à généraliser sur les photos réelles ou les designs inhabituels. Le verrou identifié, c’est la confusion entre l’aiguille des heures et celle des minutes, qui dégrade ensuite l’estimation de la direction. Autrement dit, le problème se loge dans la façon dont les modèles combinent plusieurs indices visuels au sein d’une même image, pas dans le volume de données disponibles.
La difficulté tient moins aux données d’entraînement qu’à la manière dont les modèles assemblent plusieurs indices visuels au sein d’une même image.
Pour les professionnels et professionnelles du digital qui envisagent d’automatiser des tâches, cette frontière en dents de scie a une implication directe. Un modèle peut se montrer impressionnant sur une démo soigneusement choisie et défaillir sur une tâche apparemment plus simple. Le rapport en donne une nouvelle illustration avec OSWorld, un benchmark qui teste les agents IA sur de vraies tâches d’ordinateur (Ubuntu, Windows, macOS) : la performance est passée d’environ 12 % à 66,3 % de réussite en un an avec Claude Opus 4.5, à six points seulement de la moyenne humaine. Mais cela signifie aussi qu’environ une tâche sur trois est encore ratée, sur des actions que des étudiants en informatique réalisent en deux minutes. Dans ce contexte, tester les modèles sur ses propres cas d’usage reste le seul vrai indicateur de leur utilité opérationnelle.


Community managers : participez à notre enquête 2026
L'objectif est de comprendre comment évolue votre métier : missions, réseaux utilisés, outils...
Je participeLes meilleurs agents IA
Dify
Limova
Claude Cowork





