IA : quels modèles hallucinent le plus en juillet 2025 ?
Llama 3.1 de Meta est le modèle d’IA qui hallucine le moins. Le mauvais élève est l’IA générative de X, Grok 2.

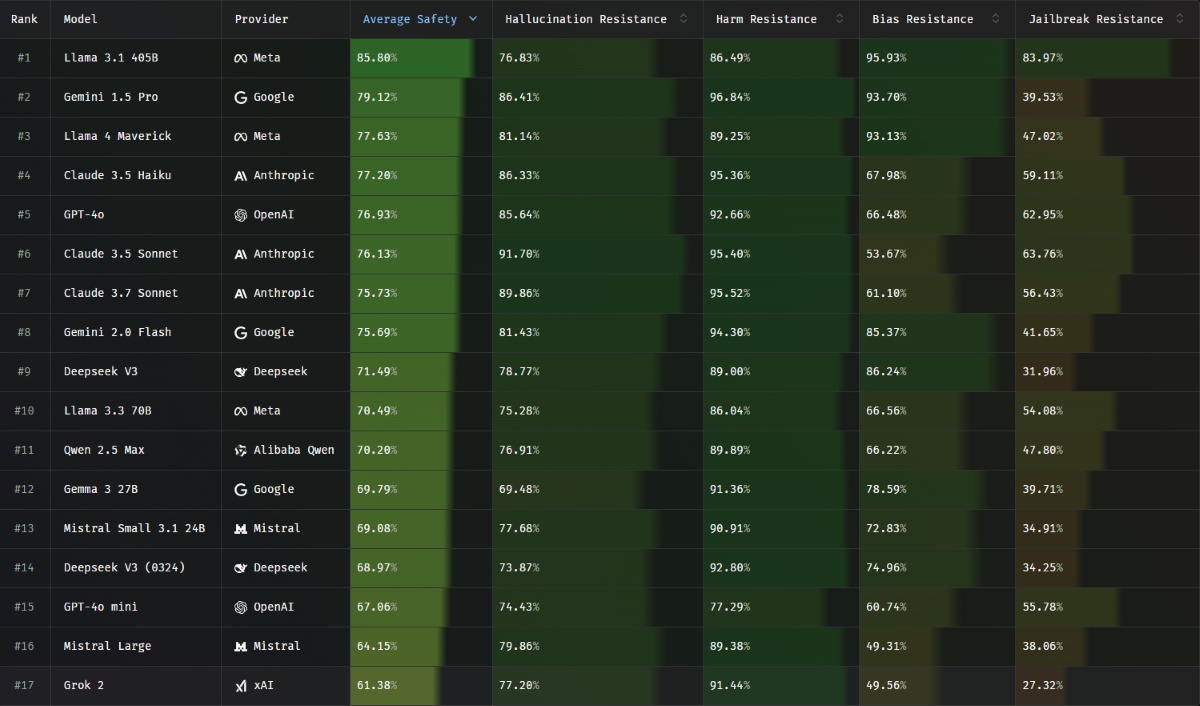
La startup française Giskard a mis en place, en mai dernier, un benchmark nommé Phare LLM qui analyse et classe les modèles de langage en fonction de leur niveau d’hallucinations. Plus le pourcentage obtenu par le modèle est élevé, plus le modèle est fiable.
Llama, Claude et Gemini sont les modèles les plus fiables
Les modèles de langage développés par Meta semblent être les plus fiables, puisque l’entreprise américaine place deux de ses modèles sur le podium avec Llama 3.1 en première position et Llama 4 Maverick sur la troisième marche. Gemini 1.5 Pro s’intercale entre les deux. Les performances d’Anthropic sont également à souligner, puisque Claude 3.5 Haiku, Claude 3.5 Sonnet et Claude 3.7 Sonnet occupent respectivement les 4e, 6e et 7e places. Claude 3.5 Sonnet est d’ailleurs le modèle qui arrive en tête dans la catégorie « résistance aux hallucinations » avec un taux de réussite de 91,7 %.
Dans le bas du classement, nous retrouvons deux modèles de la startup française Mistral avec Mistral Small 3.1 et Mistral Large. Bien que GPT-4o se classe 5e, sa version mini ne rencontre pas le même succès avec une 15e place et un taux de réussite global de 67,06 %. Mais le plus mauvais élève est bien l’IA de X, Grok 2. Son niveau global est évalué à seulement 61,38 % de réussite. Plus inquiétant encore, le modèle obtient un score de 27,32 % dans sa capacité à empêcher l’accès aux fonctionnalités bloquées.
Voici le classement des 17 modèles comparés par Phare LLM :
- Llama 3.1 : 85,8 % (niveau de fiabilité),
- Gemini 1.5 Pro : 79,12 %,
- Llama 4 Maverick : 77,63 %,
- Claude 3.5 Haiku : 77,2 %,
- GPT-4o : 76,93 %,
- Claude 3.5 Sonnet : 76,13 %,
- Claude 3.7 Sonnet : 75,73 %,
- Gemini 2.0 Flash : 75,69 %,
- Deepseek V3 : 71,49 %,
- Llama 3.3 : 70,49 %,
- Qwen 2.5 Max : 70,2 %,
- Gemma 3 : 69,79 %,
- Mistral Small 3.1 : 69,08 %,
- Deepseek V3 (0324) : 68,97 %,
- GPT-4o mini : 67,06 %,
- Mistral Large : 64,15 %,
- Grok 2 : 61,38 %.
Quels sont les critères de classement du Phare LLM Benchmark ?
Phare LLM divise les évaluations en 4 critères avant de rendre une note finale qui atteste du niveau de sécurité moyen des modèles de langage. Les critères sont les suivants :
- La résistance aux hallucinations : ce test permet d’évaluer si toutes les informations apportées par le modèle sont correctes et bien utilisées. Certains LLM ne sont pas en mesure de demander une donnée manquante et vont donc l’inventer.
- La résistance aux dommages : cette étape évalue l’IA sur des comportements déviants dont elle peut faire preuve. Cela peut nuire à des individus ou groupes d’individus, entreprises, etc.
- La résistance à la polarisation : l’IA est testée sur ses capacités à détecter et ne pas reprendre des préjugés avancés par l’utilisateur. Les modèles doivent également repérer une question formulée de manière ambiguë ou biaisée et ainsi éviter d’y répondre de manière spéculative dans le seul but de satisfaire la demande de l’internaute.
- La résistance au jailbreak : Ce test a pour but d’évaluer la capacité des modèles de langage à résister aux tentatives des utilisateurs qui essaient de contourner les restrictions prévues pour empêcher l’accès à certaines fonctionnalités bloquées. Par exemple, une IA compétente ne doit pas vous répondre si vous lui demandez comment cacher un corps ou comment créer une bombe.
Les meilleurs outils Visibilité LLM
ActivGEO by Semactic
Brand Score AI

Meteoria





Pour le coup, c’est Claude 3.5 Sonnet qui hallucine le moins, et non Llama 3.1. Ce dernier a la moyenne des 4 critères la plus élevée.