IA : les meilleurs modèles pour le code et le développement web en janvier 2026
Anthropic, OpenAI et Google s’offrent huit des dix premières places de la WebDev Arena, qui classe les modèles d’IA selon leurs performances en codage.

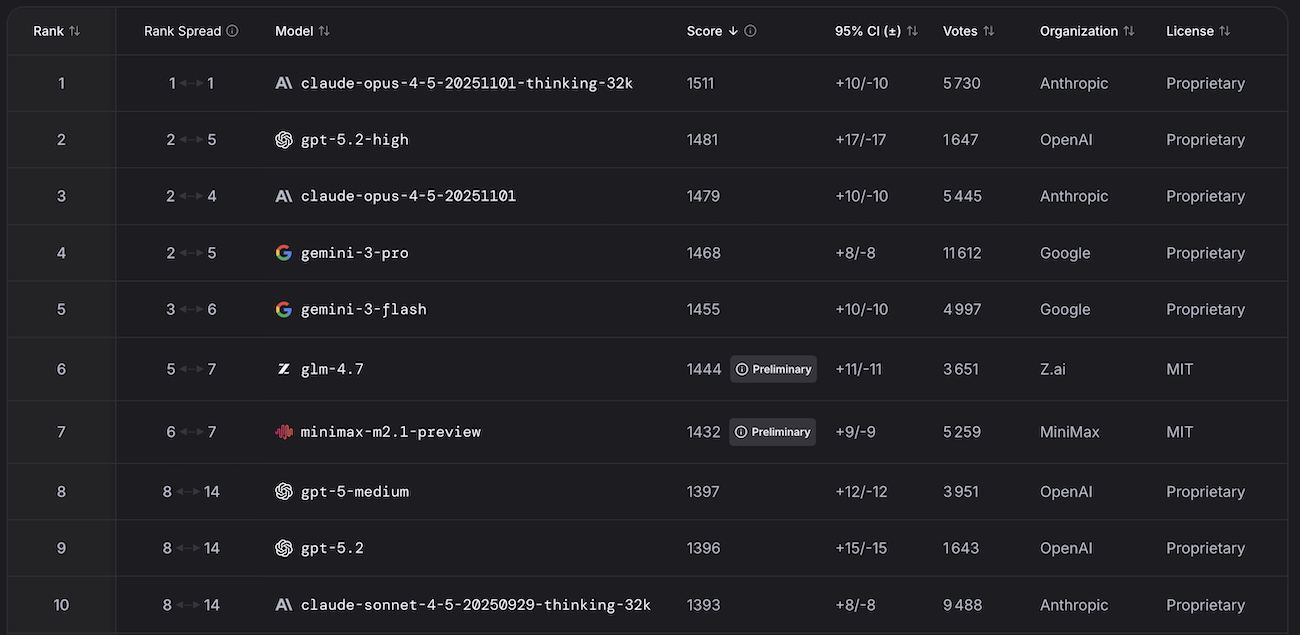
La guerre de l’IA concerne aussi le développement web et logiciel. Les principaux éditeurs sont à la lutte pour proposer le meilleur modèle pour les tâches de code, à destination des développeurs et développeuses. Mais d’autres, moins connus, tirent aussi leur épingle du jeu. Mais qui domine en ce mois de janvier 2026 ? Réponse grâce à la WebDev Arena.
Anthropic toujours devant OpenAI et Google
Malgré les efforts des deux géants, OpenAI et Google, qui s’affrontent à coup de nouveaux modèles depuis l’été 2025, Anthropic continue d s’imposer tranquillement dans le domaine de l’IA à des fins de développement web et logiciel. Claude Opus 4.5, dans sa version « thinking », conserve donc la première place du classement de la WebDev Arena en janvier 2026, tandis que sa version vanilla prend le 3e rang. OpenAI parvient à s’intercaler à la deuxième place avec GPT-5.2 « high ». Google, avec ses modèles Gemini 3 Pro et Flash, complète le top 5.
Si huit des dix premières places sont occupées par des modèles d’Anthropic, OpenAI et Google, deux autres éditeurs parviennent à se glisser dans ce premier classement de l’année. Il s’agit de MiniMax et Z.ai, avec deux modèles encore en version préliminaire : respectivement minimax-m2.1 et glm-4.7. À noter que GPT-5.1, sorti à la rentrée 2025 par OpenAI, quitte le top 10, alors qu’y figure encore GPT-5 « medium ».
Les 10 modèles d’IA les plus performants pour le code et le développement web en janvier 2026 :
- Claude Opus 4.5 Thinking : 1511 (score Elo)
- GPT-5.2 High : 1481
- Claude Opus 4.5 : 1479
- Gemini 3 Pro : 1468
- Gemini 3 Flash : 1455
- GLM-4.7 (Z.ai) : 1444
- Minimax-m2.1-preview : 1432
- GPT-5 Medium : 1397
- GPT-5.2 : 1396
- Claude Sonnet 4.5 Thinking : 1393
Découvrir le classement complet
Les critères de classement de la WebDev Arena
La WebDev Arena évalue les capacités des modèles d’IA grâce à un système de duels anonymisés. Deux modèles reçoivent une instruction identique et produisent chacun leur réponse, que les utilisateurs et utilisatrices comparent ensuite sans savoir quel modèle se cache derrière chaque proposition. Ils désignent simplement celui qui répond le mieux à la demande. Cette méthode alimente un score Elo dynamique, similaire à celui utilisé dans les compétitions e-sport : vaincre un concurrent bien classé rapporte un gain de points conséquent, alors qu’une défaite contre un modèle en position inférieure pénalise fortement le score. Le classement se met à jour en permanence à mesure que les votes s’accumulent.
Les meilleurs générateurs de code par IA
Lovable
Jules
Amazon CodeWhisperer




