IA : les 10 modèles de langage les plus performants en juillet 2024
GPT-4o mini, le modèle plus léger et moins coûteux d’OpenAI, s’invite sur la seconde marche du podium de la Chatbot Arena. Il déloge Claude 3.5 Sonnet, son principal concurrent.

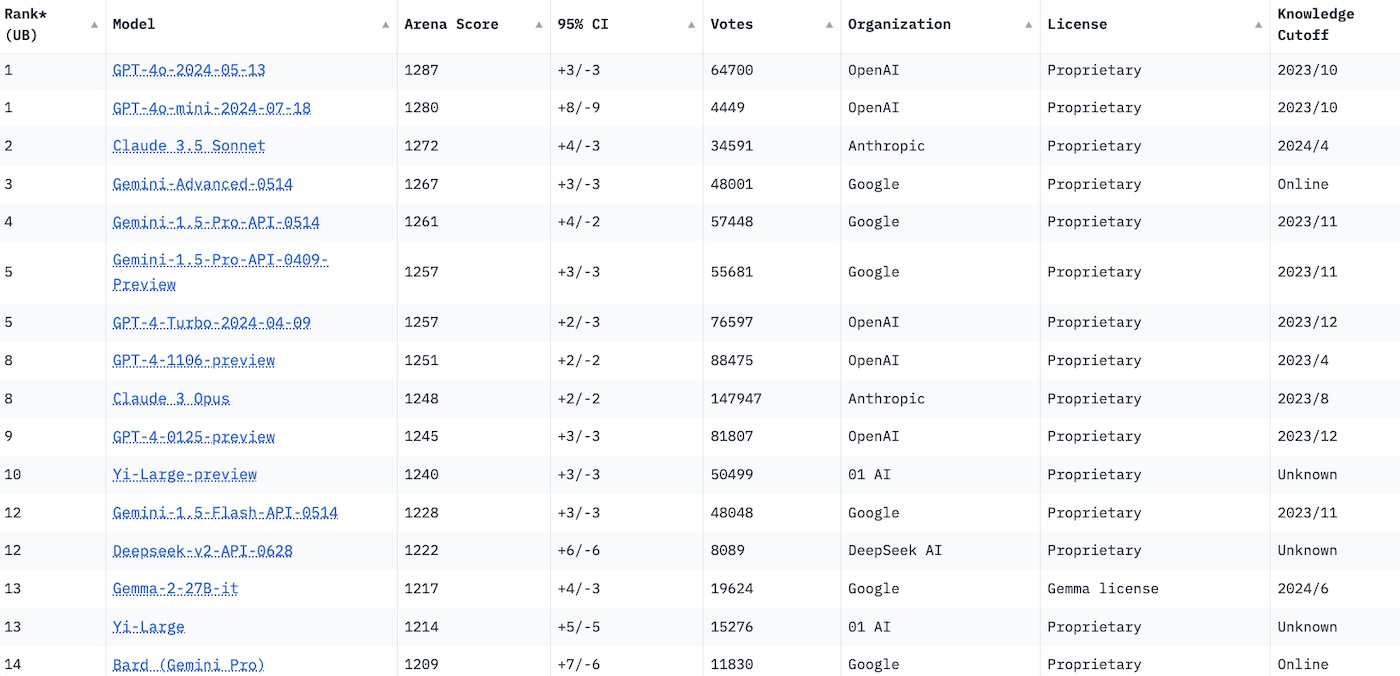
Bousculé au dernier pointage par Anthropic et son nouveau modèle Claude 3.5 Sonnet, OpenAI écrase de nouveau la Chatbot Arena, le classement conçu par des chercheurs et étudiants de l’Université de Berkeley et soutenu par Hugging Face, qui vise à évaluer objectivement les modèles génératifs les plus performants du marché grâce aux contributions des utilisateurs.
Lors de la dernière mise à jour, son modèle GPT-4o mini, réputé moins coûteux, plus léger et dévoilé ce jeudi 18 juillet 2024, s’est immédiatement placé en seconde position derrière son « grand frère » GPT-4o, l’autre technologie de pointe alimentant ChatGPT. Une performance dont s’est réjoui Sam Altman, PDG d’OpenAI, sur X.
we try not to get too excited about any one eval, but excited to see GPT-4o mini so close to GPT-4o performance on lmsys at 1/20th the price! https://t.co/5ynjPw29Ls
— Sam Altman (@sama) July 23, 2024
Pour afficher ce contenu issu des réseaux sociaux, vous devez accepter les cookies et traceurs publicitaires.
Ces cookies et traceurs permettent à nos partenaires de vous proposer des publicités et des contenus personnalisés en fonction de votre navigation, de votre profil et de vos centres d’intérêt.Plus d’infos.
Les 10 modèles de langage les plus performants en juillet 2024
Grâce cette entrée fracassante, OpenAI accapare désormais cinq des dix premières positions du classement, excluant au passage Yi Large, le modèle d’origine chinoise qui occupait jusqu’alors la dixième position. Le reste du classement est occupé par Google, qui truste les quatrième, cinquième et sixième positions grâce aux différentes itérations de Gemini, le modèle qui alimente l’agent conversationnel éponyme, et par la startup Anthropic.
Son modèle Claude 3.5 Sonnet, dépeint comme “exceptionnel dans la rédaction de contenu de haute qualité avec un ton naturel et compréhensible” et réputé comme étant un sérieux concurrent de GPT-4o, conserve sa place sur le podium au mois de juillet 2024. Le précédent modèle le plus avancé de l’agent conversationnel d’Anthropic, Claude 3 Sonnet, se maintient aussi dans la première partie de tableau.
- GPT-4o : 1287 (score Elo)
- GPT-4o mini : 1280
- Claude 3.5 Sonnet : 1272
- Gemini Advanced : 1267
- Gemini 1.5 Pro 0514 : 1261
- Gemini 1.5 Pro 0409 : 1257
- GPT-4 Turbo : 1257
- GPT-4 1106 : 1251
- Claude 3 Opus : 1248
- GPT-4 0125 : 1245
Comment la Chatbot Arena évalue-t-elle les différents modèles ?
Le fonctionnement de la Chatbot Arena repose sur un principe de « duel » : les utilisateurs sont invités à comparer anonymement deux modèles de langage, puis à identifier celui qui répond le plus précisément à leur requête initiale.
En s’appuyant sur les résultats, la Large Model Systems Organization (LMSYS), à l’origine du projet, leur attribue un score Elo. Soit l’équivalent d’une cote provisoire, qui évolue en fonction des performances et « permet de prédire l’issue du match », précise LMSYS, car elle reflète la probabilité qu’un modèle génératif remporte sa prochaine rencontre. Ainsi, si un modèle X ayant un score Elo élevé subit une défaite contre un modèle Y supposément plus faible, il perd des points Elo et chute au classement. À l’inverse, s’il remporte un duel contre un adversaire théoriquement plus fort, il engrange des points.
Ce système Elo, largement adopté dans l’esport et les compétitions d’échec, est également utilisé par Artificial Analysis, l’organisation qui s’attache à classer les modèles de génération d’images par IA.
Les meilleurs outils Visibilité LLM
ActivGEO by Semactic
Brand Score AI

Meteoria





