IA : les 10 modèles de langage les plus performants en avril 2024
Suite au déploiement d’une mise à jour, GPT-4 Turbo redevient le modèle de langage le plus performant du marché, selon la Chatbot Arena.

Pour aider les utilisateurs à évaluer la qualité des grands modèles de langage (LLM) disponibles sur le marché, la Large Model Systems Organization (LMSYS), composée d’étudiants et de chercheurs de l’Université de Berkeley, aux États-Unis, a lancé la Chatbot Arena. Soutenu par Hugging Face et déployé en mars 2024, ce projet vise à classer objectivement les LLM, tels que GPT-4, Claude 3 ou Llama-3, en s’appuyant sur les avis d’utilisateurs. Concrètement, il est demandé aux visiteurs de la plateforme de déterminer, parmi deux modèles de langage, celui qui semble être le plus performant sur la base d’un prompt identique. Après un mois, la Chatbot Arena a déjà recueilli 800 000 contributions, ce qui permet de déceler quelques tendances.
Les 10 modèles de langage les plus performants en avril 2024
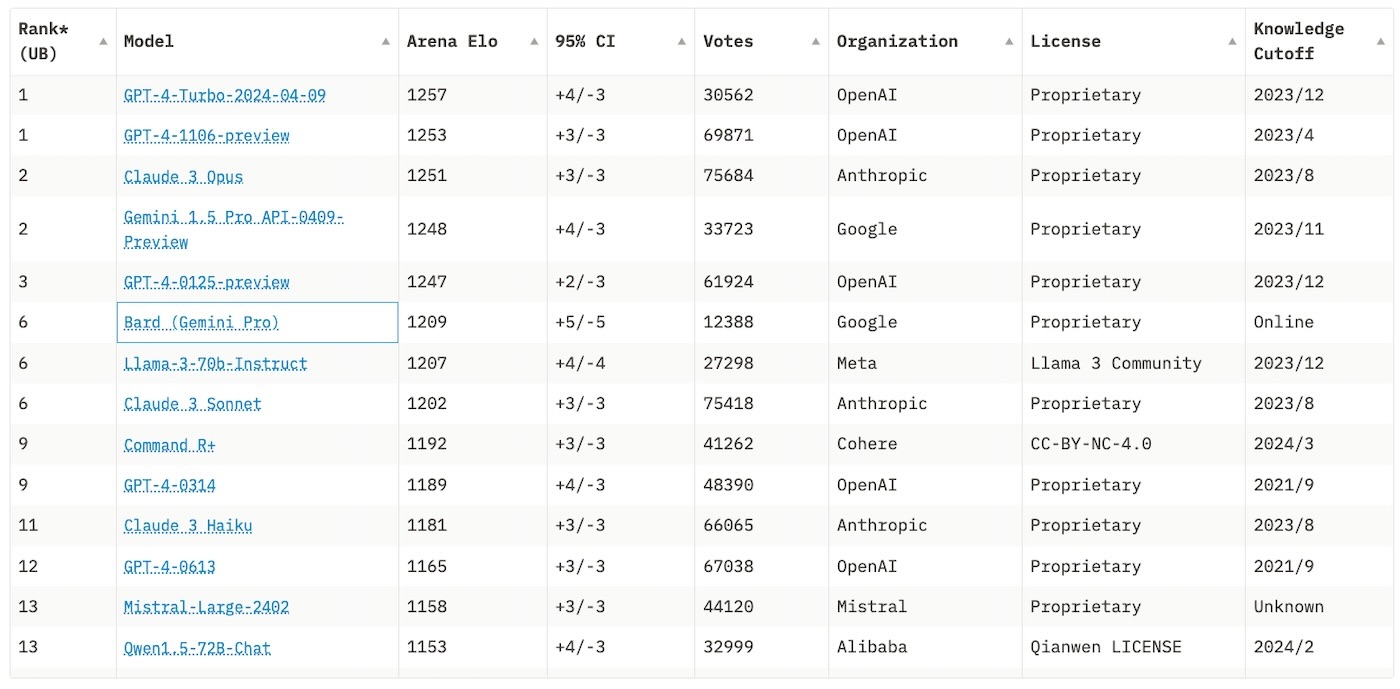
Fin mars, la Chatbot Arena avait déjà recueilli plus de 400 000 contributions et c’était Claude 3 Opus qui, à la surprise générale, se positionnait en tête du classement. Encore indisponible en France, le modèle d’Anthropic devançait deux itérations de GPT-4, conçues par OpenAI, et Gemini Pro, développé par Google. Mais suite au déploiement, mi-avril, d’une mise à jour de GPT-4 Turbo, le grand modèle de langage d’OpenAI retrouve sa couronne. Ce mois-ci, GPT-4 Turbo, dont les capacités « en écriture, en mathématiques, en raisonnement logique et en code » ont été largement améliorées selon sa société créatrice, truste la première place, devant GPT-4 et Claude 3 Opus.
🔥Exciting news — GPT-4-Turbo has just reclaimed the No. 1 spot on the Arena leaderboard again! Woah!
We collect over 8K user votes from diverse domains and observe its strong coding & reasoning capability over others. Hats off to @OpenAI for this incredible launch!
To offer… pic.twitter.com/IxbN2Q9ecJ
— lmsys.org (@lmsysorg) April 11, 2024
Pour afficher ce contenu issu des réseaux sociaux, vous devez accepter les cookies et traceurs publicitaires.
Ces cookies et traceurs permettent à nos partenaires de vous proposer des publicités et des contenus personnalisés en fonction de votre navigation, de votre profil et de vos centres d’intérêt.Plus d’infos.
Dans le reste du classement, on observe un recul de Mistral Large. Conçu par l’entreprise française Mistral AI, le LLM qui propulse l’agent conversationnel Le Chat passe de la septième à la treizième place. L’autre évolution majeure concerne Llama 3, qui pointe à la sixième place du classement. Dévoilé ce mois-ci par Meta, ce grand modèle de langage alimente notamment l’agent conversationnel Meta AI, graduellement déployé sur WhatsApp, Instagram ou Facebook dans 13 pays anglophones. L’itération précédente, Llama-2, se plaçait en 27e position le mois dernier.
Voici la liste des modèles de langage (LLM) les plus performants en avril 2024, selon la Chatbot Arena :
- GPT-4 Turbo : 1 257 (score Elo)
- GPT-4 1106 : 1 253
- Claude 3 Opus : 1 251
- Gemini 1.5 Pro : 1 248
- GPT-4 0125 : 1 247
- Bard (Gemini Pro) : 1 209
- Llama-3 : 1 207
- Claude 3 Sonnet : 1 202
- Command R+ : 1 192
- GPT-4 0314 : 1 189
Comment la Chatbot Arena classe-t-elle les modèles de langage ?
La Chatbot Arena adopte le principe du classement Elo : un système d’évaluation historiquement utilisé pour classer les joueurs d’échecs ou de Go mais qui s’est, depuis plusieurs années, démocratisé dans les jeux compétitifs en ligne tels que League of Legends ou Starcraft. Le principe est le suivant : chaque modèle de langage se voit attribuer une cote, soit l’équivalent d’un classement provisoire. Celui-ci est déterminé en fonction de son score attribué à partir de ses précédentes confrontations, et du score des concurrents auxquels il est confronté.
En d’autres termes, si, lors d’un match, un modèle de langage parvient à vaincre un adversaire dont le score est plus élevé, il gagnera des points Elo ; s’il réalise une contre-performance contre un modèle dont l’Elo est plus faible, il en perdra. « La différence de classement permet de prédire l’issue du match, détaillent les porteurs du projet LMSYS. Le système de notation Elo est approprié, étant donné que nous avons plusieurs modèles et que nous mettons en place des duels ».


La boîte à questions sur l'IA générative
Outils, prompts, usages professionnels, comparatifs... Posez toutes vos questions à Ludovic Salenne, expert IA !
Je pose une questionLes meilleurs outils Visibilité LLM
ActivGEO by Semactic
Brand Score AI

Meteoria





