GPTBot : pourquoi les sites web bloquent le robot d’indexation de ChatGPT ?
OpenAI utilise GPTbot pour scanner des pages web et améliorer la précision de ses modèles d’IA. Le robot d’indexation a été bloqué par de nombreux sites.


GPTBot, le robot d’OpenAI qui ratisse le web
Le 8 août, OpenAI dévoilait GPTBot : un robot d’indexation capable de scanner les pages web afin d’en extraire des données. Le but de la collecte, selon l’entreprise, est d’aider« ses modèles d’intelligence artificielle à devenir plus précis », mais aussi « améliorer leurs capacités générales et leur fiabilité ». À l’époque, OpenAI précisait alors que GPTBot était capable « de filtrer et supprimer les sources qui nécessitent un accès payant, qui sont connues pour recueillir des informations personnelles identifiables (IPI) ou dont le contenu enfreint nos politiques », sans doute pour rassurer les médias d’information et plateformes quant à l’utilisation de leur contenu. Sans succès.
Car très vite, plusieurs médias généralistes prennent l’initiative de restreindre l’accès au robot d’exploration web. C’est, par exemple, le cas du New York Times, qui bloque l’accès à l’agent dès le 17 août, soit quelques jours après avoir révisé ses conditions d’utilisation afin d’interdire l’utilisation de son contenu pour entraîner des modèles d’intelligence artificielle. Plusieurs publications adoptent la même démarche, comme le média britannique The Guardian, l’américain CNN ou l’agence de presse Reuters. En France, le robot d’indexation inquiète aussi : Les Échos rapporte que Radio France a bloqué l’accès à GPTBot « à titre conservatoire », tout comme les groupes TF1, France Médias Monde et le site actu.fr, propriété de Publihebdos, filiale de Sipa-Ouest-France.
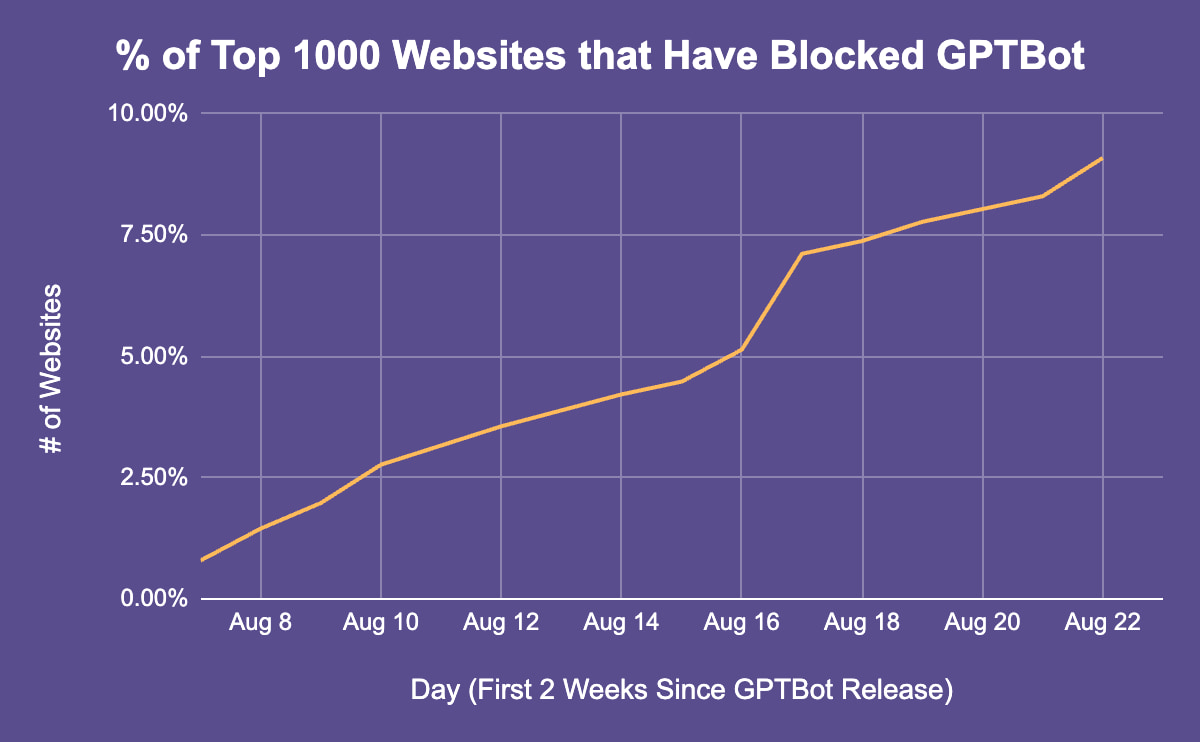
Des plateformes très consultées ont bloqué GPTBot
D’après une étude menée par Originality.ai, le ratissage de GPTBot ne préoccupe pas que les médias généralistes. En effet, l’entreprise spécialisée dans la détection de contenus générés par IA, qui a inspecté les fichiers robots.txt des 1000 sites les plus visités au monde, rapporte que 9,2 % des plateformes ont bloqué GPTBot lors de ses deux premières semaines d’exploitation. Parmi les sites qui ont restreint l’accès au robot, on retrouve notamment :
- Amazon,
- Quora,
- Shutterstock,
- WikiHow,
- Foursquare,
- Tumblr,
- Ikea,
- Airbnb,
- Lonely Planet.
Selon Originality.ai, ce pourcentage est encore plus élevé quand on s’intéresse aux sites les plus consultés. « 15 % des 100 premiers sites web vérifiés bloquent GPTBot, contre 9,2 % des 1000 premiers sites web », peut-on lire dans l’étude.
Pourquoi GPTBot inquiète ?
Comment expliquer ce climat de défiance ? Le média britannique The Guardian, qui s’est positionné publiquement sur le sujet, invoque une collecte non autorisée de données protégées par le droit d’auteur en vue d’une exploitation commerciale :
« La collecte de la propriété intellectuelle du site web du Guardian à des fins commerciales est, et a toujours été, contraire à nos conditions générales d’utilisation », explique un porte-parole du média.
Plusieurs publications, dont le New York Times, songent d’ailleurs à engager des poursuites contre OpenAI sur la question du droit d’auteur, alors que d’autres « sont actuellement en pourparlers avec des entreprises spécialisées dans l’IA pour céder leurs données en échange d’une commission, mais ces discussions ne font que débuter », rapporte Axios.
Cette défiance vis-à-vis de GPTBot, et plus largement d’OpenAI, pourrait également avoir été alimentée par la mise en pause, début juillet, de « Browse with Bing », fonctionnalité qui permettait à ChatGPT de naviguer sur le web pour fournir des réponses actualisées aux utilisateurs de l’offre premium ChatGPT Plus. La raison : cette option permettait de contourner les paywalls et « récupérer le texte intégral d’une URL » en effectuant la bonne requête, selon la firme.
We’ve learned that ChatGPT’s « Browse » beta can occasionally display content in ways we don’t want, e.g. if a user specifically asks for a URL’s full text, it may inadvertently fulfill this request. We are disabling Browse while we fix this—want to do right by content owners.
— OpenAI (@OpenAI) July 4, 2023
Pour afficher ce contenu issu des réseaux sociaux, vous devez accepter les cookies et traceurs publicitaires.
Ces cookies et traceurs permettent à nos partenaires de vous proposer des publicités et des contenus personnalisés en fonction de votre navigation, de votre profil et de vos centres d’intérêt.Plus d’infos.
Comment restreindre l’accès de GPTBot de manière partielle ou complète
Dans un blog post, OpenAI a expliqué les étapes à suivre pour bloquer l’accès au robot d’indexation. « Pour empêcher GPTBot d’accéder à votre site, vous pouvez l’ajouter au fichier robots.txt de votre site », explique OpenAI sur son site, et insérer le code User-agent: GPTBot ; Disallow: /.
Il est également possible de « permettre à GPTBot de n’accéder qu’à certaines parties de votre site », poursuit la firme, en ajoutant « le jeton GPTBot au fichier robots.txt » de votre site : User-agent: GPTBot ; Allow: /directory-1/
; Disallow: /directory-2/.
Les meilleurs outils Web scraping
Apify
Bright Data
ParseHub





