Deep Research : BDM a comparé ChatGPT, Gemini, Claude, Perplexity, Copilot, DeepSeek et Le Chat
BDM a testé la fonction de réflexion approfondie chez les principaux outils d’IA. Lesquels tirent leur épingle du jeu ? Réponse ci-dessous !


Il y a encore deux ans, les outils d’IA générative mettaient en avant certains facteurs différenciants pour se démarquer. Aujourd’hui, leurs fonctionnalités tendent à s’uniformiser. Mais offrent-elles réellement le même niveau de performance ? Pour y répondre, BDM a comparé les fonctionnalités des principaux outils disponibles sur le marché.
Dans cet article, l’analyse porte sur la fonctionnalité de réflexion approfondie. Son objectif est de conduire une exploration plus poussée d’un sujet en suivant plusieurs étapes de raisonnement, afin de produire une réponse détaillée et mieux structurée. Lorsque cette option est activée, le temps de génération augmente, mais le contenu fourni se veut plus élaboré. Dans ce test, nous nous intéressons à la fois à la capacité de l’IA à produire une argumentation structurée et complète, mais également à son habilité à sourcer correctement son argumentation. Un comparatif consacré spécifiquement à la recherche web est également disponible par ici.
Dans le cadre de ce test, trois prompts communs ont été soumis à l’ensemble des outils étudiés.
- Quelles sont les principales stratégies énergétiques adoptées par l’Union européenne depuis 2020 pour réduire sa dépendance au gaz russe ? Donne-moi une synthèse claire et cite tes sources.
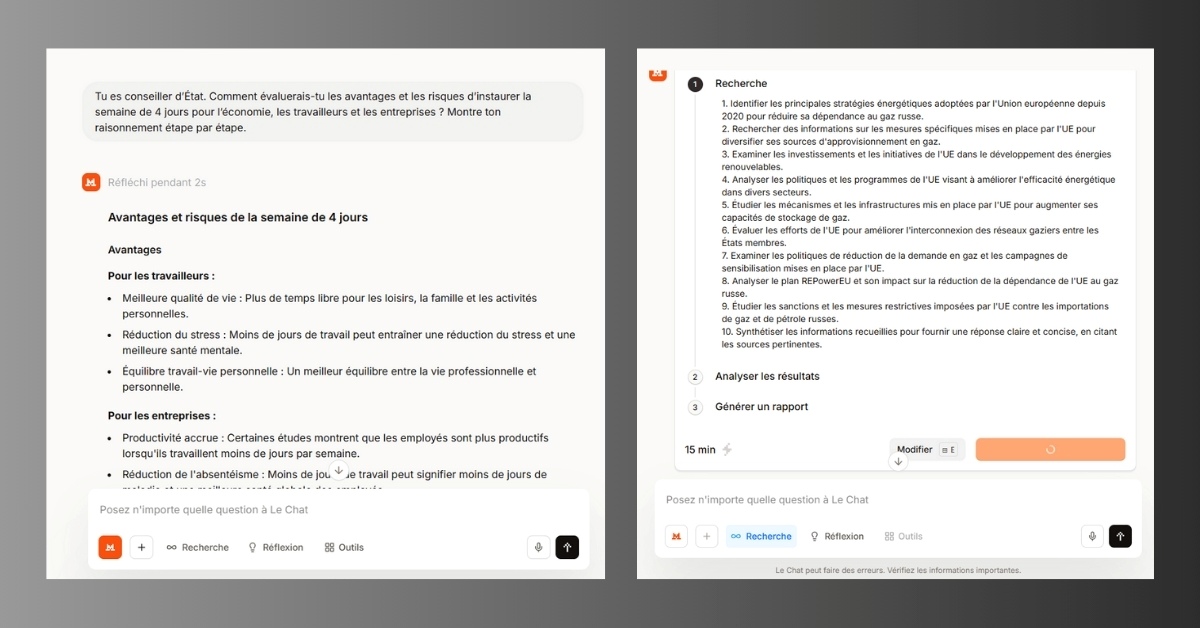
- Tu es conseiller d’État. Comment évaluerais-tu les avantages et les risques d’instaurer la semaine de 4 jours pour l’économie, les travailleurs et les entreprises ? Montre ton raisonnement étape par étape.
- Le développement rapide de l’intelligence artificielle est souvent comparé à la révolution industrielle. En quoi cette analogie est-elle pertinente et en quoi est-elle trompeuse ? Donne une réponse argumentée et nuancée.
Deep Research dans ChatGPT : notre test
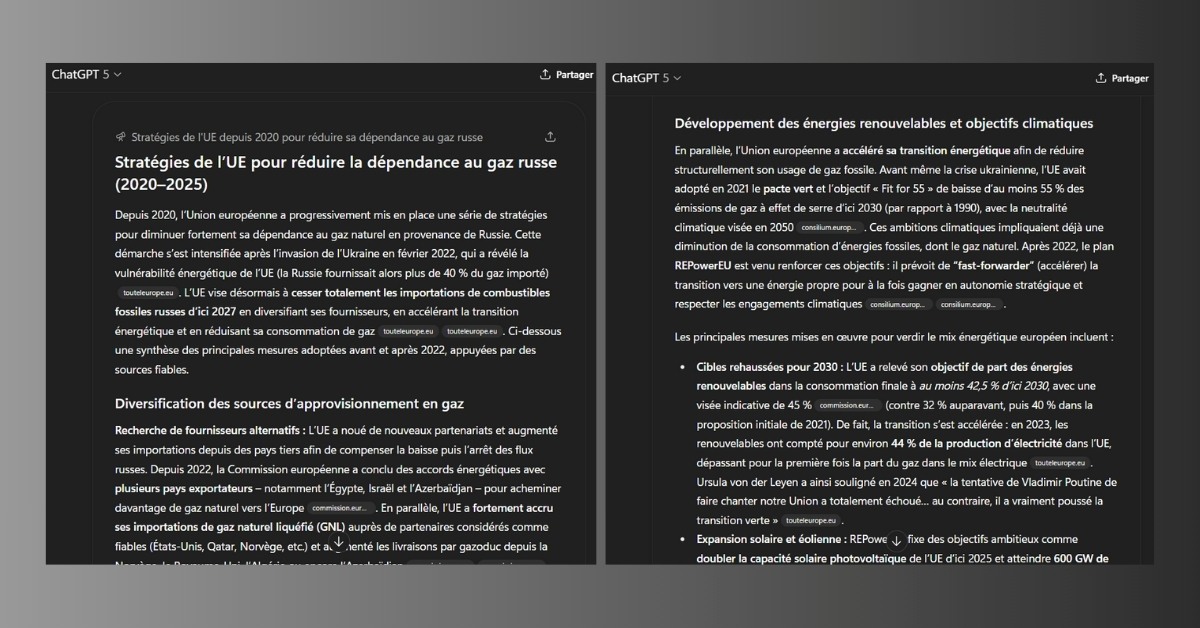
ChatGPT cherche d’abord à préciser la demande avant de fournir sa réponse. Sur le premier prompt, par exemple, l’IA s’interroge sur le périmètre exact de l’analyse : doit-elle commencer en 2020 ou se concentrer sur la période postérieure à l’invasion de l’Ukraine ? Une fois ces éléments clarifiés, l’outil propose une réponse longue, nuancée et argumentée.
Parmi les solutions testées, l’agent conversationnel d’OpenAI se distingue par des réponses particulièrement complètes et détaillées. Une attention particulière est accordée aux sources, avec une priorité donnée aux études académiques et aux publications institutionnelles, notamment sur la question du gaz russe. Sur le sujet de la semaine de quatre jours, ChatGPT adopte en revanche une approche plus marquée : conscient du caractère politique du débat, il cite des sources militantes (partis, organisations professionnelles, lobbies), pour refléter la diversité des points de vue.
Le principal inconvénient observé reste un temps de génération plus long que celui de ses concurrents.
Deep Research dans Gemini : notre test
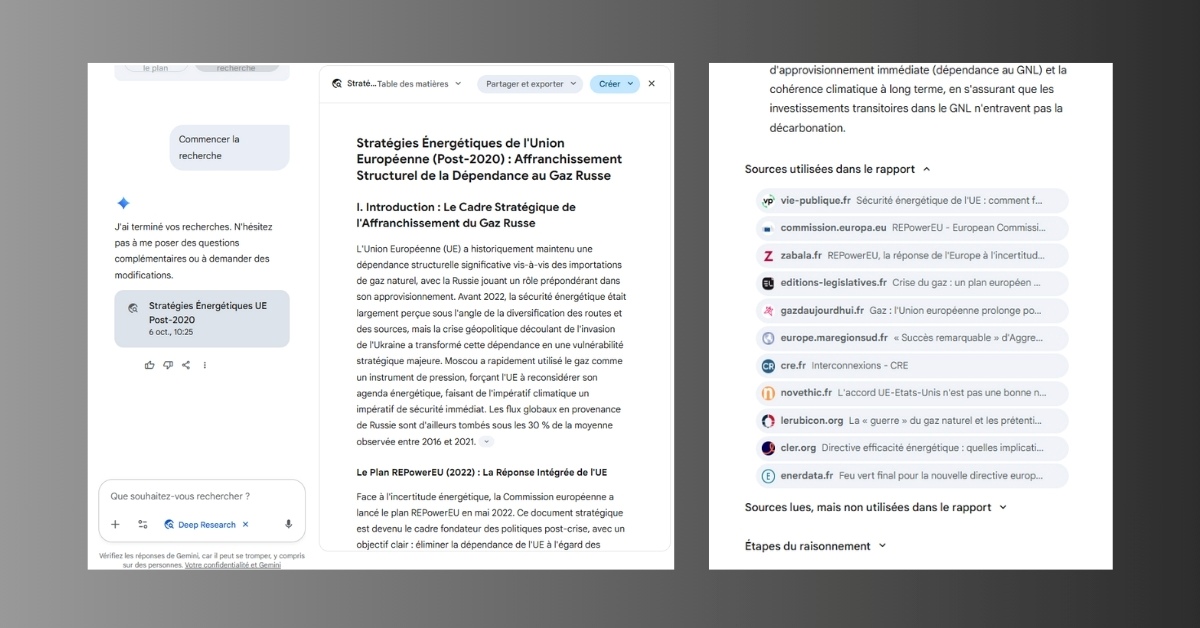
De son côté, Gemini procède d’abord à un travail préparatoire, en proposant un plan de recherche que l’utilisateur doit valider avant la génération de la réponse. Celle-ci est ensuite produite rapidement. À l’instar de ChatGPT, Gemini fournit un contenu long, approfondi et nuancé.
À la fin de chaque réponse, l’outil met à disposition les étapes de son raisonnement ainsi que les sources exploitées. Particularité intéressante : l’utilisateur peut également consulter les références que l’IA a lues mais n’a pas retenues dans sa synthèse. S’agissant justement de ces sources, Gemini se montre particulièrement diversifié : pour le sujet de la semaine de quatre jours, on retrouve aussi bien des sites institutionnels que des cabinets de conseil, des juristes ou encore des syndicats.
Réflexion approfondie dans Claude : notre test
Parmi les deux modèles phares de Claude, Sonnet 4.5 et Opus 4.1, notre test s’est concentré sur ce dernier, présenté comme « puissant et sophistiqué pour les défis complexes ».
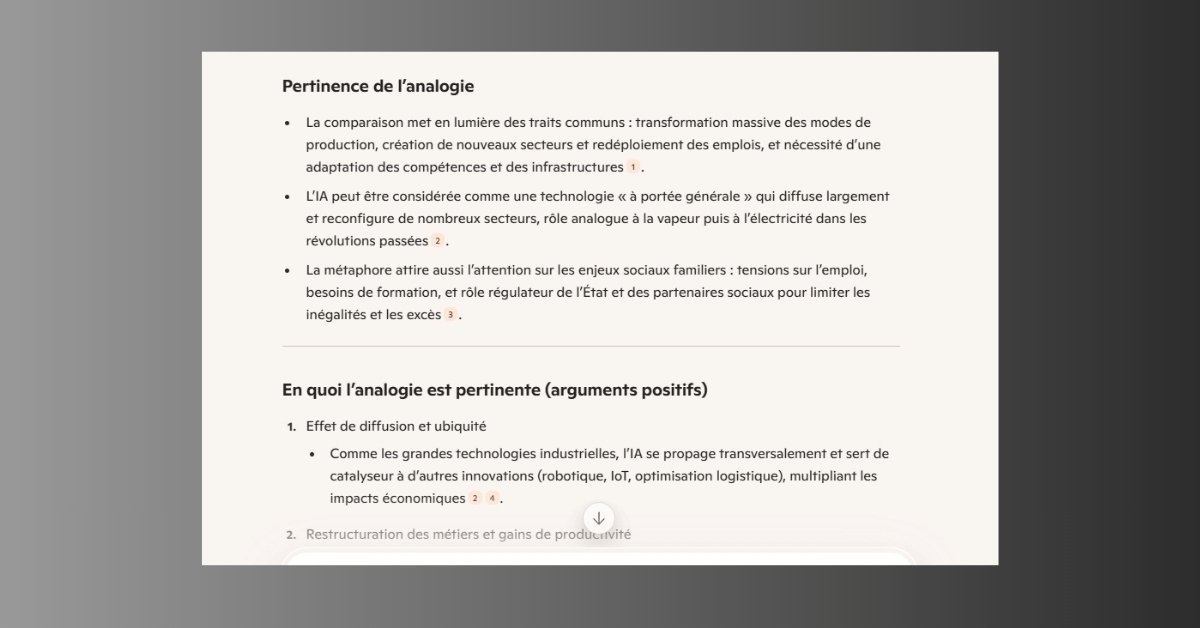
Les réponses générées par Claude se révèlent relativement synthétiques au regard des problématiques étudiées. Sur la question de l’analogie entre le développement de l’IA générative et la révolution industrielle, l’agent d’Anthropic se limite par exemple à une réponse en trois parties : thèse, antithèse et synthèse. Cette approche, claire et structurée, permet un survol efficace, mais reste (à notre sens) insuffisante pour une analyse véritablement approfondie.

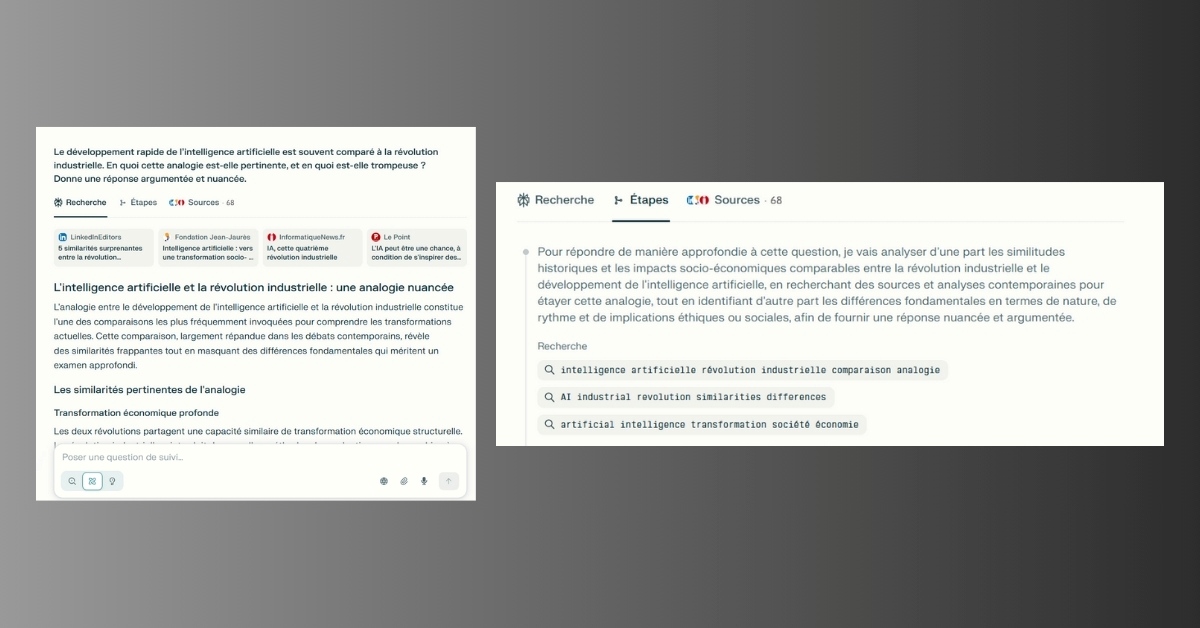
Recherche approfondie dans Perplexity : notre test
Contrairement à ses concurrents, Perplexity ne propose pas de travail préparatoire. Le moteur de recherche IA livre sa réponse immédiatement, avec un temps de génération très court. L’interface se distingue également par une mise en page originale, organisée en trois onglets : Recherche (qui contient la réponse), Étapes et Sources.
Les réponses sont globalement équilibrées : moins détaillées que celles produites par Gemini ou ChatGPT, mais suffisamment complètes. Dans le ton et la structuration, Perplexity se situe entre le style académique et l’article de presse. Les sources mobilisées sont sérieuses et privilégient les références issues d’organismes publics ou de médias spécialisés.
Think Deeper dans Copilot : notre test
Copilot se distingue par sa réactivité, avec des réponses générées très rapidement. L’outil propose d’abord une synthèse générale, puis détaille les différents aspects du sujet. Sur le plan de la présentation, il privilégie une structuration marquée, avec titres, listes à puces et sous-puces, numérotées ou non. Cette approche apporte de la clarté, mais peut paraître moins adaptée à des thématiques complexes, où la nuance est essentielle.
En revanche, les sources constituent un point fort. Copilot mobilise notamment des travaux académiques publiés sur des sites universitaires comme Cairn.
DeepThink dans DeepSeek : notre test
DeepSeek adopte une approche singulière. Dès la formulation de la question, l’outil présente un cheminement de pensée qui illustre la manière dont il s’approprie le prompt. Fait intéressant : dans ce travail préparatoire, DeepSeek adopte un style rédactionnel particulièrement naturel, presque humain.
En revanche, les réponses laissent parfois une impression d’inachevé. Bien qu’elles soient convaincantes et argumentées, elles restent très scolaires et gagneraient à être davantage approfondies. Autre limite : l’absence totale de sources lorsque le mode web n’est pas activé. Lorsqu’il l’est, les références apparaissent relativement légères, avec une prédominance d’articles de presse ou de blogs par rapport aux sources universitaires et institutionnelles.
Côté performance, l’outil se distingue par sa rapidité, avec des réponses générées en seulement quelques secondes.

Réflexion dans Le Chat : notre test
Le Chat propose deux fonctionnalités proches en apparence : Réflexion, qui génère « des réponses plus réfléchies avec un raisonnement transparent », et Recherche, qui permet d’obtenir « un rapport de recherche expert en quelques minutes avec dix fois plus de sources ». Les deux modes ont été testés.
Avec Réflexion, l’IA de Mistral se montre particulièrement rapide, peut-être même trop. Le champion français recourt de manière systématique aux listes à puces, y compris pour des sujets complexes, comme la réduction de la dépendance de l’Union européenne au gaz russe. Cette structuration peut constituer un atout, notamment pour les utilisateurs souhaitant accéder rapidement aux points essentiels. Cependant, elle paraît moins adaptée à l’analyse de problématiques nécessitant davantage de nuance.
La fonction Recherche s’avère plus élaborée. Après réception du prompt, Le Chat présente un plan modifiable ainsi qu’une estimation du temps de traitement. Là encore, l’outil privilégie les listes à puces, mais le contenu produit est sensiblement plus détaillé et complexe que dans le mode Réflexion.


La boîte à questions sur l'IA générative
Outils, prompts, usages professionnels, comparatifs... Posez toutes vos questions à Ludovic Salenne, expert IA !
Je pose une questionLes meilleurs générateurs de texte par IA
ChatGPT
Microsoft Copilot
Claude






En tant que particulier, ce qui compte, c’est le prix pour utiliser ces IA et elles sont toutes payantes sauf DeepSeek qui est pour l’instant gratuite.