Comment empêcher ChatGPT d’utiliser vos textes et images
Les IA, notamment génératrices, sont gourmandes en données pour leur entraînement. Et se gavent souvent des vôtres ! Découvrez comment l’éviter.


Les IA génératives tiennent désormais une place prépondérante dans le paysage numérique. Depuis fin 2022, elles se sont imposées et n’ont cessé de s’améliorer, répondant plus précisément aux requêtes ou générant des images toujours plus réalistes. Mais pour parvenir à de tels résultats, les modèles de langage dont sont issues ces IA ont besoin d’entraînement.
S’ils l’ont été en amont de leur déploiement public, ils continuent constamment de s’entraîner sur de nouvelles données, et peut-être bien les vôtres. C’est notamment le cas de DALL-E et ChatGPT, deux des produits d’OpenAI. Il est cependant possible d’empêcher cette récupération de data, voire « d’empoisonner ses propres données » pour les plus vengeurs !
Comment empêcher ChatGPT de s’entraîner sur vos données
Par défaut, ChatGPT utilise vos données, issues de vos conversations avec le chatbot, pour s’entraîner. Avec l’arrivée de DALL-E 3, le générateur d’images, et de la reconnaissance d’images au sein de l’agent conversationnel, OpenAI crée une boucle d’entraînement très efficace pour ses IA. Mais il est possible de refuser l’accès à vos données à ChatGPT, qui ne se formera plus dessus.
Les contrôles de données vous offrent la possibilité de désactiver l’historique des discussions et de choisir facilement si vos conversations seront utilisées pour entraîner nos modèles, lit-on sur la FAQ d’OpenAI.
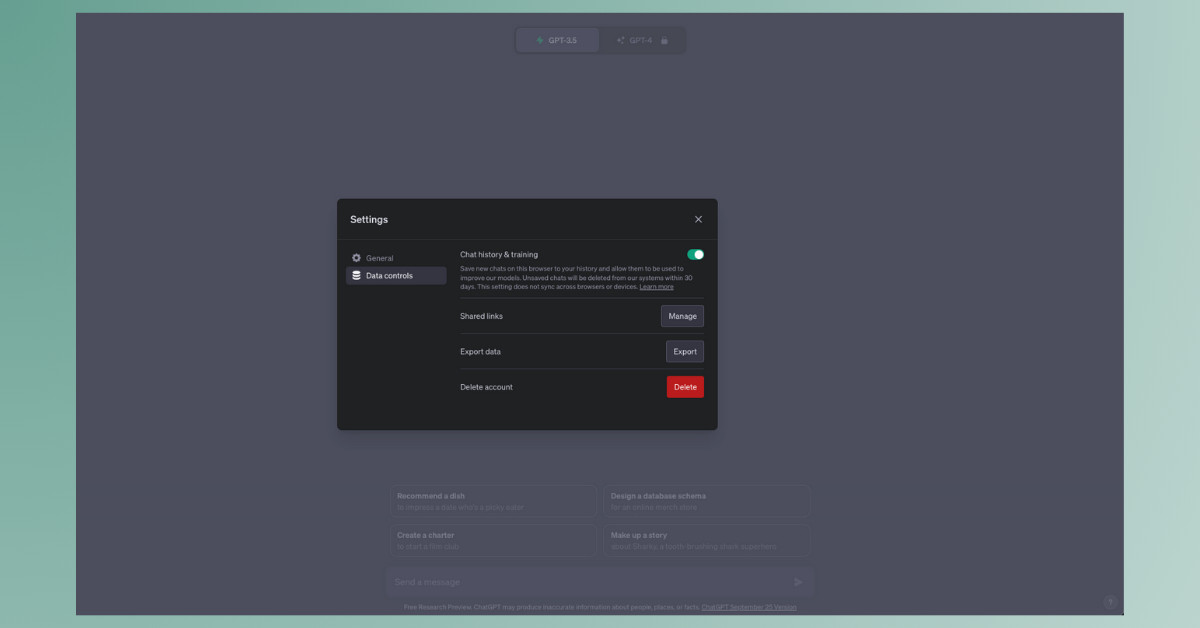
1. Sur navigateur web
Pour désactiver cet « historique des discussions », voici la marche à suivre sur navigateur web :
- Dans l’interface de ChatGPT, cliquez sur le menu sous forme de trois points en bas à gauche de votre écran, près du nom d’utilisateur, puis choisissez Settings,
- Au sein de la fenêtre qui apparaît, choisissez l’onglet Data controls,
- Décochez l’option Chat history & training.
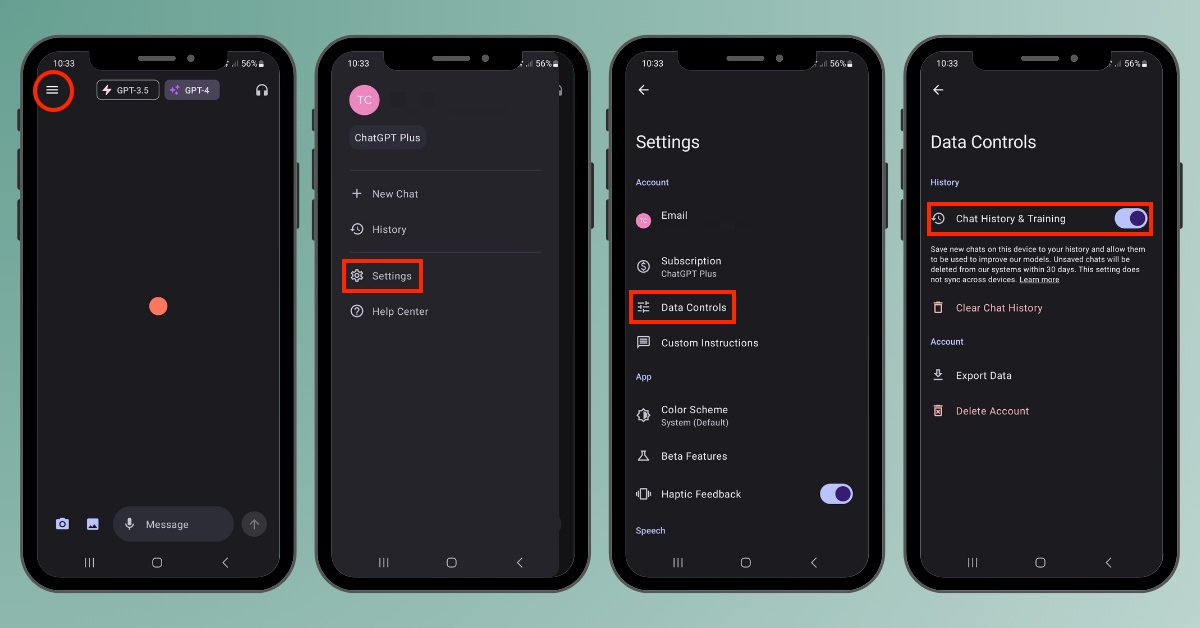
2. Sur smartphone Android
Sur l’application mobile Android, voici la procédure (voir image de une) :
- Appuyez sur le menu burger en haut à gauche de votre écran et choisissez Settings,
- Sélectionnez Data Controls,
- Décochez l’option Chat History & Training.
3. Sur iPhone
Sur l’application mobile iOS, voici comment faire :
- Appuyez sur le menu sous forme de trois points en haut à droite de votre écran et choisissez Settings,
- Sélectionnez Data Controls,
- Décochez l’option Chat History & Training.
À noter : l’action n’est pas synchronisée. Si vous utilisez ChatGPT à la fois sur navigateur web et via l’application mobile, il faudra répéter l’opération sur chaque interface.
Comment bloquer ChatGPT pour votre site et vos créations
OpenAI l’assure, « une fois que les modèles d’IA ont appris de leurs données d’entraînement, ils n’ont plus accès aux données ». Cependant, la firme dit comprendre « que certains propriétaires de contenu ne souhaitent pas que leurs œuvres accessibles au public soient utilisées pour entraîner [ses] modèles ». Pour pallier cet éventuel problème, OpenAI propose deux alternatives.
1. Bloquer l’accès de votre site web à ChatGPT
La première est d’interdire au robot d’exploration du développeur d’IA, GPTBot, de parcourir votre site à la recherche de données de formation. Partout où il est en mesure de recueillir de la data issue de sources Internet accessibles au public, GPTBot passe. Et de plus en plus de sites, notamment des grands médias, lui interdisent l’accès. Pour cela, il faut d’abord l’identifier. Voici ces petits noms :
User agent token: GPTBot
Full user-agent string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)
Pour lui interdire l’accès, ajoutez la commande suivante au robots.txt de votre site :
User-agent: GPTBot
Disallow: /
OpenAI explique la procédure complète et les actions de son robot sur cette page.
2. Utiliser le formulaire de « désinscription des artistes et propriétaires de contenu » pour protéger vos créations
La seconde alternative proposée par ChatGPT est de lui indiquer ou fournir le contenu créatif dont vous êtes l’auteur, afin qu’il soit supprimé des données de formation. Pour cela, un formulaire a été mis à disposition des artistes et des titulaires de droits par OpenAI. « Lorsque vous remplirez ce formulaire, nous examinerons votre demande et pourrons vous contacter pour des informations supplémentaires. Une fois vos informations vérifiées, nous supprimerons les images respectives des futurs ensembles de données de formation. »
Précision importante : OpenAI détient certaines licences pour des ensembles de données, qui pourraient inclure vos travaux ou images, si vous avez concédé des droits à des tiers. Le cas échéant, la firme ne sera pas en mesure de supprimer votre contenu signalé.
Empoisonner ses données contre les IA ?
Serait-ce là la « dernière défense pour les créateurs de contenu contre les web scrapers » et, par extension, l’utilisation des données pour l’entraînement des modèles de langages ? C’est ce que pense l’équipe derrière Nightshade, un outil qui corrompt les données d’une œuvre créative pour empoisonner la data de formation, et décrypté par le MIT Technology Review.
Avec Nightshade, une image représentant un chapeau pourra être comprise par l’IA comme l’image d’un chat, par exemple. À terme, un tel empoisonnement des modèles de langage pourrait totalement corrompre une IA et lui faire faire à peu près n’importe quoi. La revue américaine ajoute qu’il est particulièrement difficile de supprimer ces données empoisonnées une fois entrées dans la formation du modèle et que les dégâts sont rapides : « Avec 300 échantillons empoisonnés, un assaillant peut manipuler Stable Diffusion pour lui faire générer des images de chiens qui ressemblent à des chats. »
L’équipe derrière Nightshade a également développé Glaze, un outil qui masque le style personnel d’un artiste pour lui éviter d’être collecté par un robot. Ces deux outils fonctionnent de la même façon, en changeant des pixels des images de manière subtile et invisible pour l’œil humain, afin de manipuler le machine learning pour que le modèle interprète le visuel différemment de ce qu’il montre vraiment.


La boîte à questions sur l'IA générative
Outils, prompts, usages professionnels, comparatifs... Posez toutes vos questions à Ludovic Salenne, expert IA !
Je pose une questionLes meilleurs outils Veille
Feedly

Netvibes
Inoreader





