Le classement des modèles d’IA les plus performants en août 2025
GPT-5 a-t-il fait une entrée fracassante dans le classement des meilleurs modèles d’IA ? Ou les utilisateurs sanctionnent-ils ses faiblesses face à d’autres modèles ?

L’actualité des modèles d’IA a été marquée, en ce mois d’août 2025, par la sortie de GPT-5, qui équipe désormais ChatGPT. Mais ce modèle a montré quelques limites et subi des critiques, celles-ci se reflètent-elles dans le classement de la LMArena ? Réponse tout de suite !
Les meilleurs modèles d’IA en août 2025
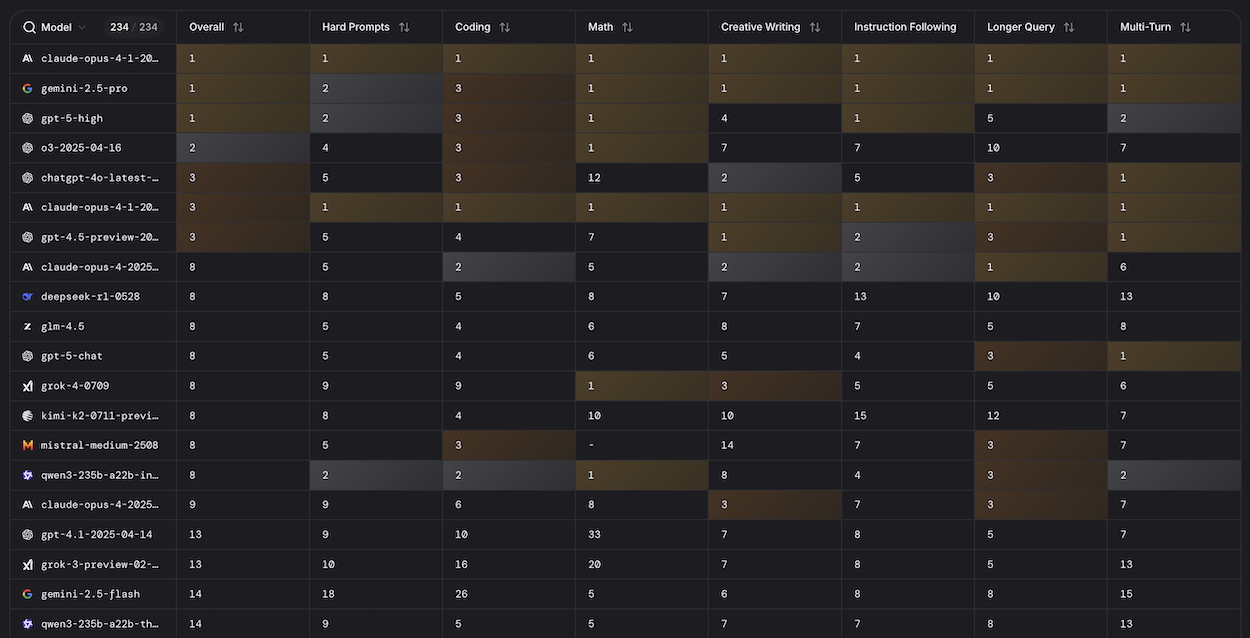
Le classement général de la LMArena est-il dominé par GPT-5 ? Pas du tout ! Le nouveau modèle d’OpenAI ne figure qu’au 3e rang ce mois-ci, dans un classement qui compile les performances des modèles autant en génération de texte, qu’en code, longues requêtes, mathématiques, etc (voir image de une). La version « high » de GPT-5 est dominée par Anthropic et son dernier modèle Claude Opus 4.1, qui s’offre la première place dans les 7 catégories de la LMArena et, donc, le rang de leader au général.
Il est suivi de près par Gemini 2.5 Pro de Google et GPT-5 d’OpenAI. Suivent ensuite les anciens modèles de ChatGPT, o3 et 4o, qui complètent le top 5. Le modèle « chat » de GPT-5, c’est-à-dire le modèle de base, ne pointe qu’à la 11e place, loin derrière la panoplie de Claude, ou encore le modèle chinois DeepSeek-R1. Un camouflet pour OpenAI, et une preuve que ses modèles GPT-5 sont loin de faire l’unanimité.
Voici le top 10 des modèles d’IA les plus performants en août 2025 selon la LMArena :
- Claude Opus 4.1 « thinking »
- Gemini 2.5 Pro
- GPT-5 « high »
- o3
- 4o
- Claude Opus 4.1
- GPT-4.5 Preview
- Claude Opus 4 « thinking »
- DeepSeek R1
- GLM-4.5
LMArena : le classement par catégorie
La LMArena propose désormais plusieurs catégories pour évaluer et classer les modèles d’IA selon leurs compétences. Voici lesquels se démarquent selon le contexte en août 2025 :
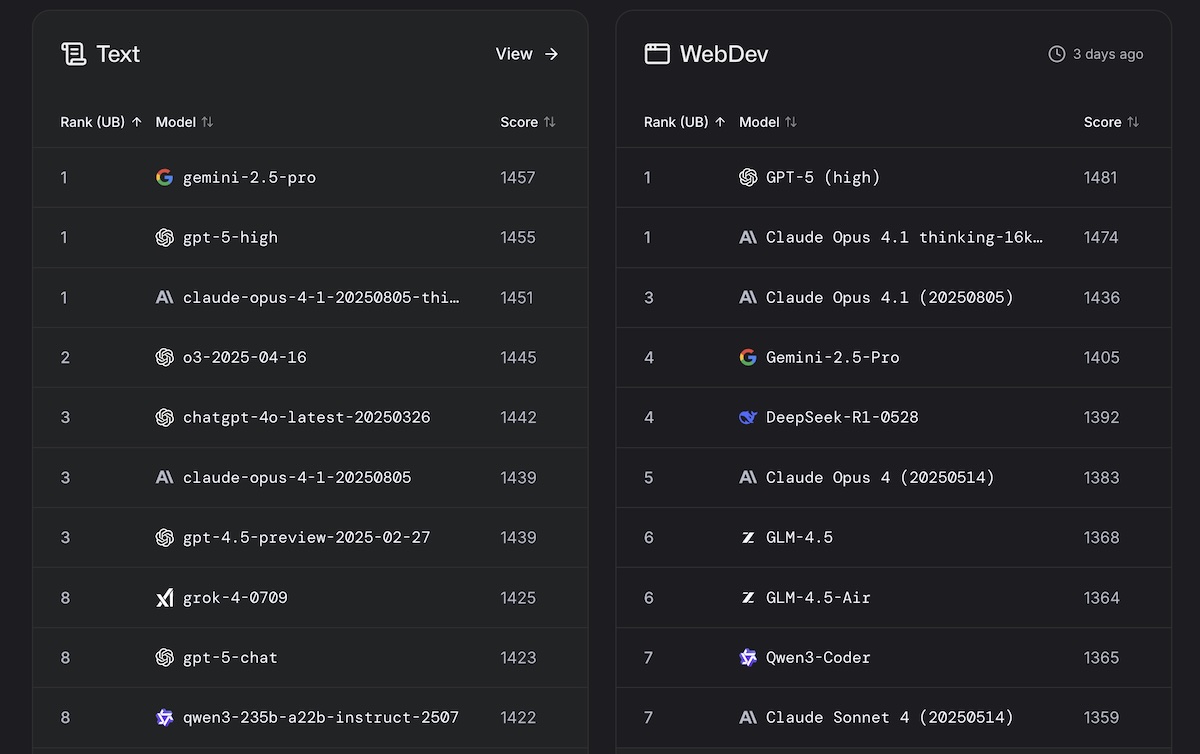
- Texte : Gemini 2.5 Pro reste leader, en s’offrant le luxe de devancer GPT-5 « high ». Claude Opus 4.1 « thinking » complète le podium, constitué de trois modèles très proches les uns des autres.
- Développement web : GPT-5 « high » est leader en termes de développement web, devant deux modèles d’Anthropic, Claude Opus 4.1 « thinking » et Claude Opus 4.1. Gemini, avec 2.5 Pro, n’est ici que quatrième.
- Analyse d’images : mais Google reprend la première place avec son modèle le plus avancé dans la catégorie de l’analyse d’image. GPT-5 montre ici ses défaillances, étant devancé par deux modèles plus anciens, 4o et GPT-4.5 Preview.
- Recherche en ligne : ici, c’est o3 Search d’OpenAI qui s’empare de la tête du classement, suivi par Claude Opus 4 et Gemini 2.5. Les deux modèles de Perplexity, Sonar, complètent le top 5.
- Génération d’images : autre surprise et désillusion pour OpenAI, la génération d’images est désormais meilleure avec Imagen 4 de Google, estiment les utilisateurs de la LMArena. Suivent, dans le top 5, Flux et Seedream.
Quels éléments déterminent le classement de la LMArena ?
La plateforme LMArena, conçue par la Large Model Systems Organization (LMSYS), s’appuie sur un principe de duels anonymes pour mesurer la qualité des modèles d’IA. Lorsqu’un utilisateur ou une utilisatrice soumet une requête, deux modèles différents répondent, sans que l’on sache lesquels, et les participant(e)s choisissent la réponse jugée la plus pertinente. Chaque confrontation modifie un score Elo, un système emprunté au monde des échecs : vaincre un adversaire mieux noté augmente la cote, tandis que perdre face à un modèle réputé plus faible la fait diminuer.
Ce procédé permet d’établir des classements séparés selon les types de tâches ou les domaines examinés. À partir de ces résultats ciblés, la plateforme produit ensuite un classement global, qui reflète la performance générale de l’ensemble des modèles en compétition.


La boîte à questions sur l'IA générative
Outils, prompts, usages professionnels, comparatifs... Posez toutes vos questions à Ludovic Salenne, expert IA !
Je pose une questionLes meilleurs outils Visibilité LLM
ActivGEO by Semactic
Brand Score AI

Meteoria





