Quand ChatGPT invente des URL : comment l’IA envoie nos lecteurs vers des pages 404
Les IA génératives inventent (aussi) des URL crédibles mais fictives. Résultat : des pages 404 à répétition. Pourquoi ce phénomène ? Et si c’était un signal éditorial à exploiter ?

En analysant nos logs de trafic, nous avons découvert que les IA génératives envoient régulièrement des lecteurs vers des pages BDM qui n’existent pas. Des centaines d’URL fantômes, toutes (ou presque) parfaitement crédibles, mais menant droit vers des erreurs 404. Pourquoi ce phénomène ? Et si ces hallucinations révélaient des contenus que vous devriez créer ?
Le constat : des URL crédibles mais inexistantes
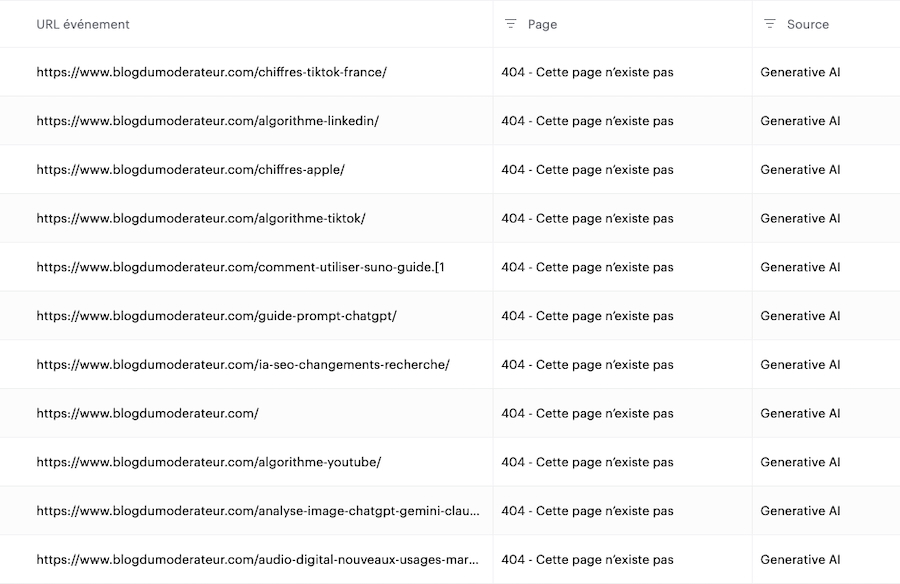
Tout est parti d’une anomalie dans nos statistiques. En regardant de près notre trafic, nous avons constaté que le nombre de visites sur des pages en erreur 404, se produisant quand la ressource n’a pas été trouvée, était en forte augmentation. En filtrant ce trafic par source, nous avons identifié que ces centaines de visites provenaient d’outils d’IA générative (comme ChatGPT, Perplexity, Gemini ou Claude) et atterrissaient sur des pages 404.
Le problème : ces URL n’ont jamais existé sur BDM. Parmi les plus fréquentes : /chiffres-tiktok-france/, /algorithme-linkedin/, /tendances-social-media-2025/. Des adresses qui ressemblent parfaitement à nos vrais articles, avec nos conventions de nommage, notre structure de slugs. Sauf qu’elles sont entièrement fictives.
Nous ne sommes pas les seuls à observer ce phénomène. Anastasia Kotsiubynska, Head of SEO chez SE Ranking, a documenté la même chose : 70 fausses URL détectées en trois mois sur son site, dont certaines avec plus de 20 sessions et même des backlinks. Selon une étude Ahrefs, les IA génératives produisent des liens cassés à un taux près de trois fois supérieur à celui de la recherche Google classique (1,01 % contre 0,15 %). Ce n’est pas un bug isolé, mais un problème systémique qui touche tous les éditeurs.
Pourquoi les LLM inventent-ils des sources ?
Pour comprendre, il faut revenir au fonctionnement de ces modèles. Les LLM, comme ceux qui alimentent ChatGPT ou Claude, ne « savent » pas les choses comme un humain. Ce sont des moteurs de prédiction statistique. Ils génèrent du texte token par token en calculant ce qui est le plus plausible compte tenu du contexte. Comme le résume une analyse de l’université Macquarie, « le LLM utilise un modèle statistique pour deviner, sur la base de probabilités, le prochain mot. La compression des données a causé une perte de fidélité, ce qui fait que le modèle produit l’énoncé le plus plausible plutôt que le plus véridique ». En clair, même si les vraies URL de BDM peuvent figurer dans les données d’entraînement, les détails exacts se perdent parfois en route.
Les modèles sont récompensés pour deviner plutôt qu’admettre l’incertitude, explique OpenAI.
Le problème est aggravé par l’absence totale de vérification intégrée. Le modèle ne consulte pas notre site pour vérifier qu’une page existe, il génère ce qui ressemble à une URL crédible. Même avec la recherche web activée, l’IA peut mélanger résultats réels et contenu fabriqué. Les études partagées par Medium convergent : selon les domaines et les modèles, entre 18 % et 69 % des citations générées sont partiellement ou totalement inventées. Dans le secteur médical, une étude a mesuré un taux de 47 % de références complètement fictives produites par ChatGPT.
Anatomie d’une hallucination : ce que révèlent nos données
En analysant les URL fantômes de notre site, on observe des patterns révélateurs. Le modèle a clairement appris nos conventions. Les slugs suivent notre structure habituelle, les thématiques correspondent à notre ligne éditoriale (social media, SEO, outils IA), malgré quelques erreurs amusantes. Certaines URL reprennent les noms des membres de notre équipe, tentant de renvoyer vers une page auteur qui existe bel et bien, mais avec un format de chemin qui n’existe pas sur notre site (ex : /author/jbillon/ au lieu de auteur/jose-billon/). L’IA a assimilé les éléments (noms, thématiques, structure) sans les assembler correctement.

D’autres URL trahissent leur origine par des artefacts suspects. On trouve par exemple comment-utiliser-suno-guide.[1 ou calendrier-2026/)[2. Des traces de crochets et de parenthèses, typiques des formats de citation numérotée. Néanmoins, la page comment-utiliser-suno-guide/ existe bel et bien chez nous : il peut donc s’agir d’une mauvaise manipulation du lien par l’IA ou d’un copier-coller raté côté utilisateur. Quoi qu’il en soit, le résultat est le même : une 404. L’université Macquarie confirme ce mécanisme de fabrication. Elle note que sur six références générées par ChatGPT lors d’un test, cinq étaient fausses. Elles combinaient des éléments réels (vrais noms d’auteurs, vrais titres de journaux) mais assemblés de façon incorrecte.
Les conséquences pour les éditeurs et les lecteurs
Pour un éditeur, chaque URL hallucinée représente une opportunité manquée. Un visiteur qualifié, envoyé par une IA qui le croyait pertinent, atterrit sur une page d’erreur et repart. Pire, il peut croire que le site est mal maintenu ou que le contenu a été supprimé. L’image de marque en souffre sans que l’éditeur n’y soit pour rien.
Dans les cas les plus graves, les conséquences dépassent le simple trafic perdu. En 2023, l’affaire Mata contre Avianca a marqué les esprits. Un avocat new-yorkais a été sanctionné après avoir soumis un mémoire juridique contenant six citations de cas complètement inventés par ChatGPT, avec des noms de parties et des extraits de décisions qui n’ont jamais existé.
Côté lecteur, le risque est plus insidieux. Quand une IA cite une URL d’un média notoirement fiable pour appuyer une affirmation, beaucoup d’utilisateurs ne cliquent même pas. Le nom du média suffit à crédibiliser l’information. Ils repartent convaincus, sans savoir que la source n’a jamais réellement existé. Une forme de désinformation invisible pour l’utilisateur qui ne découvre jamais, ou trop tard, qu’il a été induit en erreur. Qu’il perde ou non son temps à chercher un contenu introuvable, sa confiance s’érode, envers l’IA mais encore plus envers le média cité à tort.
Et si ces hallucinations étaient un signal SEO ?
Jusqu’ici, on a parlé du problème. Mais certains professionnels du référencement y voient une opportunité. L’hypothèse étant que si une IA génère spontanément une URL comme /algorithme-linkedin/ sur votre domaine, c’est qu’elle a appris que ce contenu « devrait » exister chez vous. Le modèle a capté une attente, celle des utilisateurs, reflétée dans ses données d’entraînement. En quelque sorte, les hallucinations peuvent devenir un signal de demande éditoriale, une forme involontaire de gap analysis.
C’est l’approche défendue par Anastasia Kotsiubynska de SE Ranking : « Si une URL hallucinée attire du trafic significatif ou des backlinks, créer cette page peut capturer une opportunité que les systèmes IA ont identifiée pour vous. » Elle évoque une approche pragmatique, en ignorant les URL avec une ou deux visites, et en redirigeant celles qui génèrent du trafic répété en envisageant de créer le contenu si le gap éditorial est réel. Serait-ce un nouveau KPI à surveiller pour les éditeurs ?
La question éthique reste ouverte. En créant le contenu a posteriori, on « récompense » d’une certaine manière l’hallucination. On valide un système qui fabrique des sources fictives. La frontière entre opportunisme et bonne pratique éditoriale est floue, mais pour un média qui surveille déjà les requêtes Google sans résultats, exploiter les 404 générées par l’IA n’est finalement qu’une extension logique de la veille SEO.
Comment vérifier ses sources à l’ère de l’IA
Pour les professionnels qui utilisent l’IA au quotidien, quelques réflexes simples limitent les risques. D’abord, toujours cliquer sur les URL avant de les citer ou de les partager. Une évidence souvent oubliée dans l’urgence. Ensuite, croiser les références avec des bases fiables, ou simplement effectuer une recherche directe sur le site source. Enfin, il faut se méfier des citations trop parfaites. Les vraies références, notamment académiques, comportent souvent des irrégularités de formatage que les hallucinations, trop lisses, n’ont pas.
Pour les lecteurs, le conseil est plus simple encore : ne jamais accorder de crédit à une source sans avoir vérifié qu’elle existe. L’IA génère ce qui est plausible, pas ce qui est vrai. Tant que cette limite existera, la vigilance restera de mise.
Les meilleurs réducteurs d'URL
TinyURL
Bitly

URLz






Merci pour cet article.
En fait depuis très longtemps mon site reçoit des sollicitations de pages qui n’existent pas, de la part de robots de Google principalement.
Ils agissent comme pour « voir ce que ça donne ».
Les cibles sont généralement des url de recherche par mots clés au sein de mon site.
Par exemple si une url existante est « annuaire/recherche=restaurant+bord+de+mer/ »
Un crawler peut très bien tester « annuaire/recherche=restaurant+bord+de+mer+pizzeria/ »
C’est pour moi un signe d’intérêt. Ma base de données va créer cette page et la lui fournir.
Quel que soit son statut HTTP (200,301,410) cette page existera définitivement.
Franck,
Dans ce cas, je me réjouis qu’un crawler appelle la page annuaire/recherche=drogue+et+armes+a+feu (ou d’autres trucs illicites, illégaux, pénalement répréhensibles, etc.). C’est une forme d’injection de données similaire à la mésaventure connue par Castorama il y a près de 10 ans : https://www.franceinfo.fr/internet/castorama-victime-d-un-acte-de-malveillance-de-son-moteur-de-recherche_1489989.html
Une bonne idée, pour repérer les hallucinations des sources de LLMs, et décider ce qu’on veut en faire, c’est de s’appuyer sur l’analyse des logs. Nils Talibart a publié un article sur le sujet il y a quelques jours : https://redirection.io/fr/blog/comment-identifier-les-pages-de-son-site-citees-comme-source-par-chatgpt-et-les-llm