Détruit-on vraiment la planète quand on dit « merci » à ChatGPT ?
La question de l’impact environnemental des IA génératives comme ChatGPT inquiète, mais leur consommation réelle reste difficile à évaluer. Les prompts réalisés sur le chatbot sont-ils vraiment si énergivores ?


Le 16 avril dernier, sur X, un utilisateur s’est interrogé : « Je me demande combien d’argent OpenAI a perdu en frais d’électricité à cause des gens qui disent « s’il vous plaît » et « merci » à leurs modèles. » Une interrogation à laquelle Sam Altman a répondu avec une touche d’humour, en indiquant que cela représentait « des dizaines de millions de dollars bien dépensés — on ne sait jamais ». Il n’en fallait pas moins pour relancer la discussion sur le coût environnemental des IA génératives. Si de simples formules de politesse peuvent générer de telles dépenses en électricité, qu’en est-il des chatbots dans leur globalité ? Nous vous proposons ici quelques éléments de réponse.
Consommation d’énergie sur ChatGPT : de quoi parle-t-on ?
À chaque requête sur ChatGPT, des serveurs puissants sont sollicités. Hébergés dans des centres de données répartis dans le monde, ces équipements, conçus pour des calculs intensifs, tournent en continu et nécessitent une alimentation électrique constante, ce qui génère des gaz à effet de serre.
Cette consommation inclut non seulement les calculs effectués, mais aussi le refroidissement indispensable pour éviter la surchauffe. Ces systèmes de climatisation, très énergivores, alourdissent l’empreinte carbone. À cela s’ajoute le transfert de données à travers des infrastructures numériques, elles aussi alimentées en électricité.
L’impact environnemental de ChatGPT repose donc sur deux niveaux :
- La pollution liée à la conception, concentrée au moment de l’entraînement du modèle, représente un coût massif mais ponctuel. Elle est indépendante des utilisateurs finaux.
- À l’inverse, la pollution liée à l’usage, répétée à chaque interaction, s’accumule au fil du temps. Les utilisateurs en sont directement responsables. Mais d’une certaine manière, elle amortit la consommation d’énergie engendrée par la construction du modèle.
ChatGPT : l’impact environnemental de l’entraînement des modèles
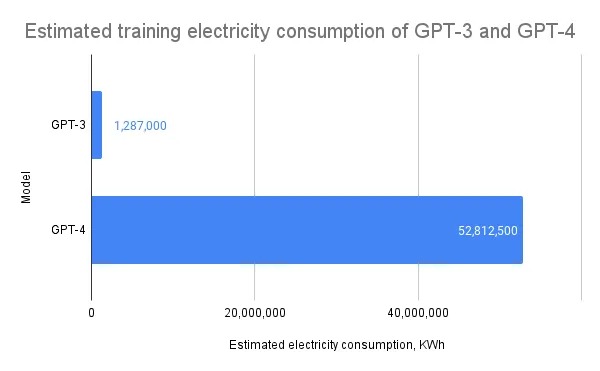
Depuis quatre ans, un certain nombre de travaux (plus ou moins rigoureux) ont tenté d’estimer l’énergie consommée pour créer ChatGPT. Dès 2021, une étude conjointe menée par des chercheurs de Google et de l’Université de Berkeley estimait que l’entraînement de GPT-3, avec ses 175 milliards de paramètres, avait nécessité environ 1 287 MWh d’électricité, ce qui équivaut à la consommation annuelle de 120 foyers américains.
Et les modèles suivants n’ont fait qu’accentuer cette consommation d’énergie. Le data scientist Kasper Groes Albin Ludvigsen a notamment estimé, dans un article publié sur Medium, que l’entraînement de GPT-4 aurait consommé entre 51 et 62 millions de kWh, donc 40 à 48 fois la consommation de GPT-3. Cela représente entre 24 600 et 29 600 tonnes de CO₂, soit l’équivalent d’environ 12 300 à 14 800 allers-retours Paris–New York.
La consommation d’un prompt : que pèse une question à ChatGPT ?
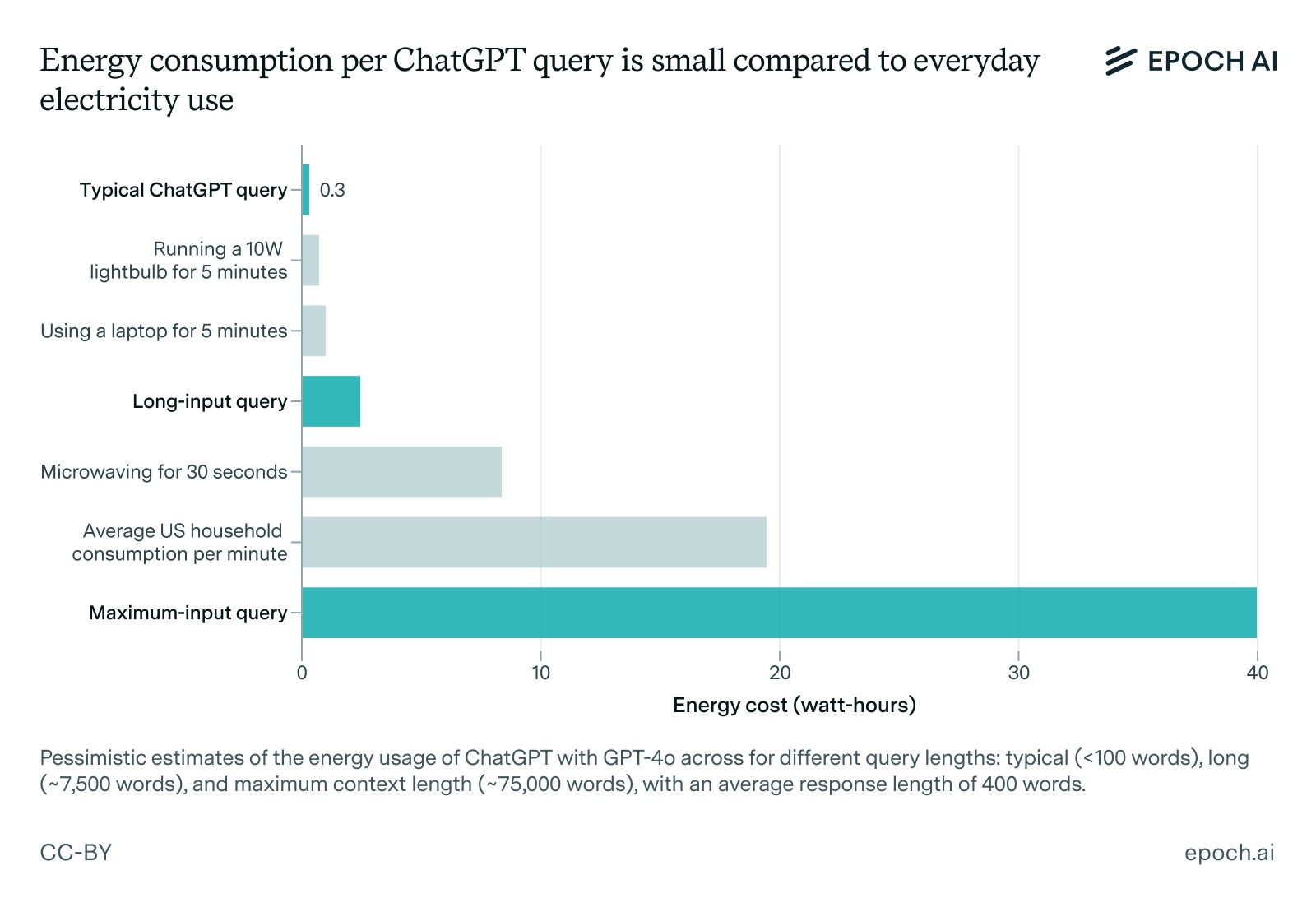
Si les modèles utilisés par ChatGPT se révèlent particulièrement polluants en phase de production, qu’en est-il de leur utilisation quotidienne ? Certaines estimations pessimistes semblent indiquer que les conversations avec les utilisateurs sont particulièrement coûteuses en énergie. En mars 2024, dans Le Figaro, l’expert en finance durable et professeur à l’ESSCA Dejan Glavas affirmait notamment qu’une requête réalisée sur ChatGPT émettrait « soixante fois plus de carbone » qu’une recherche Google. Une donnée qui, à elle seule, est de nature à dissuader de dire « merci » au chatbot.
Pour autant, les évaluations de l’impact réel d’un prompt sont variables, et un certain nombre d’entre elles incluent par exemple le coût environnemental de la formation des modèles, ce qui peut fausser le résultat. Dans une publication du 7 février 2025, l’institut de recherche indépendant Epoch AI, qui analyse l’évolution de l’intelligence artificielle et ses impacts sur la société, remet en cause certaines estimations, qu’il juge surévaluées. Selon ses calculs, une requête typique adressée à ChatGPT consommerait environ 0,3 watt-heure, soit dix fois moins que les chiffres régulièrement avancés. Cette différence s’explique par l’amélioration des modèles et des puces utilisées, et par une réévaluation plus réaliste du nombre de tokens générés lors d’une interaction typique. Le chiffre reste ainsi marginal comparé à la consommation quotidienne d’un foyer américain moyen, estimée à plus de 28 000 wattheures par jour.
À titre de comparaison, 0,3 watt-heure représente moins que la quantité d’électricité consommée par une ampoule LED ou un ordinateur portable en quelques minutes. Et même pour un gros utilisateur, le coût énergétique de ChatGPT ne représente qu’une petite fraction de la consommation globale d’électricité d’un habitant d’un pays développé, est-il indiqué dans le rapport.
Les modèles légers : une alternative plus durable ?
Une grande partie de la consommation des intelligences artificielles génératives est donc due aux ressources utilisées pour entraîner les modèles. Dès lors, les entreprises sont-elles en mesure de limiter l’utilisation des ressources tout en préservant les performances ? À cet égard, DeepSeek semble avoir montré la voie. Alors que la tendance était aux modèles de plus en plus lourds, la société chinoise est parvenue à se faire un nom grâce à des modèles plus légers, qui affichent des performances souvent proches de celles fournies par ChatGPT.
Pour réussir une telle prouesse, DeepSeek a combiné plusieurs stratégies :
- Un tri rigoureux des données d’entraînement : DeepSeek a privilégié des jeux de données structurés, de haute qualité (code propre, textes cohérents, documentation technique), ce qui a permis au modèle d’apprendre plus efficacement avec moins de données.
- Une architecture optimisée pour l’efficacité : le modèle utilise une structure ajustée (par exemple, attention locale ou semi-locale), qui réduit la complexité des calculs tout en maintenant des performances solides sur les tâches ciblées.
- L’utilisation de techniques de compression avancées : DeepSeek utilise la distillation, où un petit modèle apprend à imiter un modèle plus grand ; le pruning, qui consiste à supprimer les parties inutiles du réseau de neurones ; et la quantification, qui réduit la précision des calculs (en passant, par exemple, de 32 à 8 bits) pour gagner en vitesse et en légèreté.
- Une spécialisation sur des tâches précises : DeepSeek se concentre sur des domaines comme le raisonnement logique, la génération de code ou les réponses à des questions, ce qui lui permet d’optimiser les performances sans viser une trop forte polyvalence.
Les modèles allégés tracent ainsi une piste pertinente, mais les gains environnementaux se heurtent encore à des limites en termes de performance. Le lancement de GPT-5, attendu cette année, dira si l’écart de puissance observé entre GPT-3 et GPT-4 reste la norme, ou si une autre approche peut émerger ; auquel cas nous pourrons dire « merci » à OpenAI.
Les meilleurs outils Chatbot
Zoho SalesIQ
ManyChat
Dydu





