Comment la Chatbot Arena est devenue le TripAdvisor de l’IA
Créé par des étudiants américains, ce classement censé évaluer objectivement les performances des modèles de langage est devenu particulièrement scruté par les cadors de l’IA. Mais il n’échappe pas à certaines critiques.

Internet adore les jeux de piste, surtout lorsqu’ils sont déclenchés ou amplifiés par une figure influente. Le 30 avril 2024, en confiant avoir « un faible pour gpt2 » dans un message énigmatique posté sur X, Sam Altman, PDG d’OpenAI, relance les spéculations autour d’un mystère qui intrigue depuis deux jours les communautés de 4chan, Reddit, X, ainsi que les médias spécialisés : l’apparition discrète sur la Chatbot Arena d’un modèle baptisé « gpt2-chatbot ». Une technologie aux capacités visiblement bluffantes et dont personne n’a, jusqu’ici, revendiqué la paternité.
i do have a soft spot for gpt2
— Sam Altman (@sama) April 30, 2024
Pour afficher ce contenu issu des réseaux sociaux, vous devez accepter les cookies et traceurs publicitaires.
Ces cookies et traceurs permettent à nos partenaires de vous proposer des publicités et des contenus personnalisés en fonction de votre navigation, de votre profil et de vos centres d’intérêt.Plus d’infos.
Plus rapide, plus efficace, capable de résoudre « un problème des Olympiades internationales de mathématiques en une fois », s’étonne un utilisateur, ou de créer un clone de Flappy Bird, rapporte un autre, ce mystérieux chatbot fait sensation sur cette plateforme qui permet de tester et comparer les IA en les confrontant sur une même requête. Très vite, les suiveurs avancent qu’il s’agit du successeur de GPT-4. Et qu’il a été discrètement testé sur le comparateur avant d’être officiellement déployé. La vérité, attendue, ne tarde pas à éclater : le 13 mai 2024, en marge d’une conférence de presse, un cadre d’OpenAI confirme que le mystérieux modèle n’était autre que GPT-4o, qui vient d’être officiellement présenté et alimente encore aujourd’hui ChatGPT. L’opération de communication, qui agace certains, est finement orchestrée. Elle illustre, surtout, l’importance grandissante de la Chatbot Arena dans l’écosystème de l’intelligence artificielle.
GPT-4o is our new state-of-the-art frontier model. We’ve been testing a version on the LMSys arena as im-also-a-good-gpt2-chatbot 🙂. Here’s how it’s been doing. pic.twitter.com/xEE2bYQbRk
— William Fedus (@LiamFedus) May 13, 2024
Pour afficher ce contenu issu des réseaux sociaux, vous devez accepter les cookies et traceurs publicitaires.
Ces cookies et traceurs permettent à nos partenaires de vous proposer des publicités et des contenus personnalisés en fonction de votre navigation, de votre profil et de vos centres d’intérêt.Plus d’infos.
Entre terrain d’expérimentation et vitrine technologique
Imaginée par Wei-Lin Chiang et Anastasios Angelopoulos, deux étudiants de l’Université de Berkeley, la Chatbot Arena est devenue, en l’espace de quelques mois, un véritable laboratoire pour les grands noms de l’IA. De Google à OpenAI en passant par xAI, tous y ont testé des modèles, sans les dévoiler, avant leur déploiement à grande échelle. Avec son classement mis à jour en temps réel, elle joue aussi le rôle d’une vitrine où, après une mise à jour majeure, un cador peut y exhiber fièrement sa domination du marché.
À l’origine, le projet lancé en avril 2023 est pourtant modeste. Il vise à confronter Vicuna – un modèle développé dans le cadre d’un projet de recherche – à d’autres technologies open source. Mais en une semaine, à la grande surprise de ses créateurs, il enregistre plus de 4 700 votes grâce à une approche ludique, presque addictive, qui n’a plus évolué depuis : deux modèles anonymisés s’affrontent sur une même requête, l’utilisateur choisit la meilleure réponse, puis découvre leur identité. En fonction des performances, chaque modèle reçoit un score Elo, l’équivalent d’une cote évolutive qui reflète ses performances lors des duels. Un système déjà largement utilisé dans les compétitions d’échecs ou d’esport, et qui ajoute un soupçon de gamification supplémentaire. Avec cette formule, le projet ne tarde pas à susciter de l’intérêt au-delà des cercles universitaires. En mars 2024, lorsque BDM lui consacre un premier article, la Chatbot Arena a déjà réuni plus de 400 000 contributions. Et ses premières positions ne sont plus campées par Vicuna ou d’autres technologies open source, mais bien par les cadors de l’industrie, comme Anthropic, OpenAI ou Google.
Le box-office des modèles d’intelligence artificielle
L’ambition de Wei-Lin Chiang et Anastasios Angelopoulos, qui n’ont à l’époque pas encore validé leur doctorat, n’a pourtant jamais été de pondre un classement que les spécialistes de l’IA suivent comme le box-office, mais de rendre « les grands modèles d’IA accessibles à tous en co-développant des modèles ouverts, des jeux de données, des systèmes et des outils d’évaluation« , peut-on lire sur la page de présentation de LMSYS, l’organisme à but-non lucratif créé, à l’époque, pour chapeauter le projet. Ce n’est qu’en constatant les limites des benchmarks, ces moyens d’évaluation académiques et standardisés, censés mesurer les performances des modèles d’IA sur des tâches, comme la résolution de problèmes mathématiques ou la compréhension de texte, que les deux camarades de chambre entrevoient l’intérêt de développer un classement alimenté par des contributions humaines.
« Les benchmarks actuels ne répondent pas de manière satisfaisante aux besoins des modèles les plus avancés, en particulier en ce qui concerne l’évaluation des préférences des utilisateurs », écrivent-ils dans un article de recherche publié en mars 2024. Une manière de défendre leur méthode face à des outils largement utilisés par l’industrie mais opaques, difficiles à interpréter pour le grand public et moins fiables qu’ils n’ont pu l’être, comme l’observait le Washington Post : « D’après les chercheurs, les benchmarks académiques ont perdu de leur utilité au fil du temps, car leurs questions se retrouvent désormais dans les grands modèles de langage (LLM) qui alimentent les applications d’IA. Ce qui leur permet, en somme, d’en apprendre les réponses à l’avance. »
Si la Chatbot Arena est maintenant particulièrement scrutée, et que son principe a depuis été calqué, notamment par Artificial Analysis pour les modèles de génération d’images, c’est sans doute parce qu’elle parvient à transformer une réalité complexe en un système lisible et universel, qui permet à chacun de situer instantanément un modèle dans la hiérarchie. Le tout, en racontant implicitement une histoire, avec ses champions, ses outsiders, ses coups de théâtre et ses déclins. « Les maisons de disque ont le Billboard 100. Le football universitaire a son classement des playoffs. L’intelligence artificielle, elle, a un site web géré par deux étudiants, appelé Chatbot Arena, s’en amusait le Washington Post.
De nombreux cadres et ingénieurs suivent la Chatbot Arena comme les traders de Wall Street surveillent les marchés.
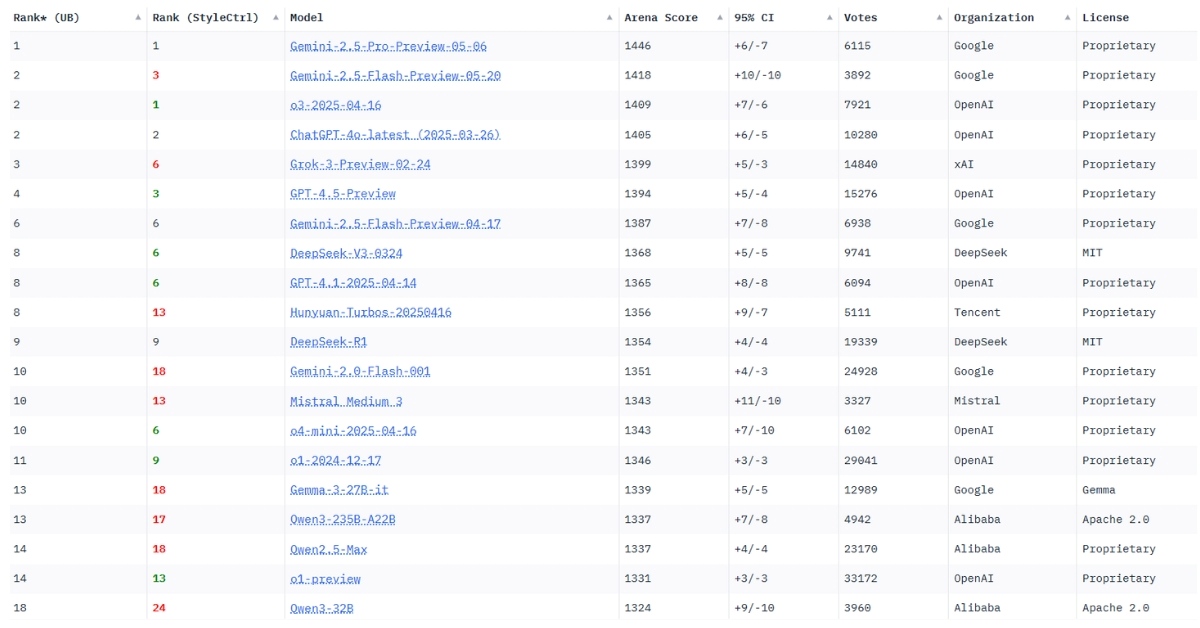
Le classement dans la Chatbot Arena, un argument commercial
Pour des acteurs comme OpenAI, Google ou Meta, pleinement engagés dans une course technologique où chaque longueur d’avance, même minime, peut valoir de l’or, l’initiative de LMSYS a tout d’une aubaine : elle fournit un indicateur pour démontrer la supériorité de leurs derniers modèles. Et ils ne s’en privent plus : lors de la présentation de Gemini 2.5, fin mars, Google n’a pas manqué de souligner – au milieu d’un blog post qui conserve ses sempiternels tableaux et graphiques cryptiques – que son « modèle d’IA le plus intelligent » s’était hissé en tête de la Chatbot Arena. Toujours en mars, Elon Musk s’était félicité que le modèle alimentant Grok, le chatbot conçu par son entreprise xAI, truste momentanément la première position du leaderboard. Une énième preuve que ce classement nourri par plus de 3 millions de votes depuis sa création – même si LMSYS semble avoir arrêté le décompte – est devenu une véritable obsession dans l’écosystème. « Tout le monde cherche à atteindre le sommet de ce classement », confirme Joseph Spisak, cadre de Meta Platforms, dans les colonnes du Washington Post.
Grok is #1 and continues to improve.
The results are based on a version of Grok that is 2 weeks old. Significant improvements since then. https://t.co/aj3rhrp83L
— Kekius Maximus (@elonmusk) February 22, 2025
Pour afficher ce contenu issu des réseaux sociaux, vous devez accepter les cookies et traceurs publicitaires.
Ces cookies et traceurs permettent à nos partenaires de vous proposer des publicités et des contenus personnalisés en fonction de votre navigation, de votre profil et de vos centres d’intérêt.Plus d’infos.
Un arbitre pas complètement fiable ?
Érigée en arbitre et affichant officiellement une position neutre, LMSYS – qui a récemment abandonné son statut d’organisme à but non-lucratif pour créer une entreprise indépendante, nommée LMArena – n’échappe pourtant pas aux critiques ces derniers mois. Il est notamment reproché à la structure ses liens jugés ambigus avec plusieurs acteurs de l’écosystème. Bien que partiellement financé par des bourses universitaires, LMArena a également reçu des donations de la part de la part du fonds d’investissement Andreessen Horowitz, qui a mis des billes dans Mistral AI, ou de Kaggle, la plateforme de data science détenue par Google, rappelle TechCrunch.
La fiabilité du système, essentiellement basé sur les préférences des utilisateurs, qui sont par nature subjectives, a également été remise en question par plusieurs chercheurs. Ils pointent également du doigt la composition de l’échantillon, qu’ils estiment peu représentatif du grand public, la popularité de la Chatbot Arena restant largement confinée aux cercles des initiés.
On aurait pu lancer Chatbot Arena en 1998 et parler déjà de grands changements de classement ou de modèles très puissants, mais ils auraient été médiocres, juge Mike Cook, maître de conférences spécialisé dans l’IA au King’s College de Londres, dans les colonnes de TechCrunch.
Bien qu’imparfaite, la Chatbot Arena comble un vide : celui d’une évaluation objective de technologies désormais omniprésentes, mais dont la complexité dépasse notre compréhension. Mais pour rester crédible, prouver sa fiabilité et son indépendance, elle devra sans doute affiner sa méthodologie et élargir son périmètre. À défaut, elle pourrait n’être qu’un instrument de communication dans une guerre des modèles de plus en plus féroce.
Les meilleurs outils Chatbot
Zoho SalesIQ
ManyChat
Botnation.ai




