Pourquoi les IA ne font jamais les mêmes recommandations
Peut-on vraiment suivre sa visibilité dans ChatGPT ou l’IA de Google ? Une étude de Rand Fishkin révèle l’instabilité des classements.

Depuis deux ans, les entreprises tentent de percer le mystère de la visibilité au sein des réponses générées par les moteurs IA. Avec, à l’esprit, l’espoir d’afficher le nom de sa marque lorsqu’un utilisateur demande une recommandation aux IA. Mais ces outils sont-ils suffisamment cohérents pour que ces mesures aient un sens ? Si l’on pose cent fois la même question à une IA, obtient-on des réponses comparables ou des listes différentes à chaque fois ? Peut-on réellement parler de classement dans des systèmes conçus pour produire des réponses probabilistes ?
Dans une étude récente publiée sur SparkToro, Rand Fishkin a cherché à répondre à cette problématique. Son travail vise à évaluer la stabilité des recommandations générées par les IA et à déterminer si la visibilité d’une marque peut être mesurée de manière fiable. Voici ce qu’il en ressort.
La méthodologie de l’étude
Rand Fishkin a donc cherché à observer ce que produisent réellement les IA lorsqu’on leur pose la même question, de nombreuses fois. L’étude s’est concentrée sur trois outils parmi les plus utilisés aux États-Unis : ChatGPT, Claude et l’IA de Google.
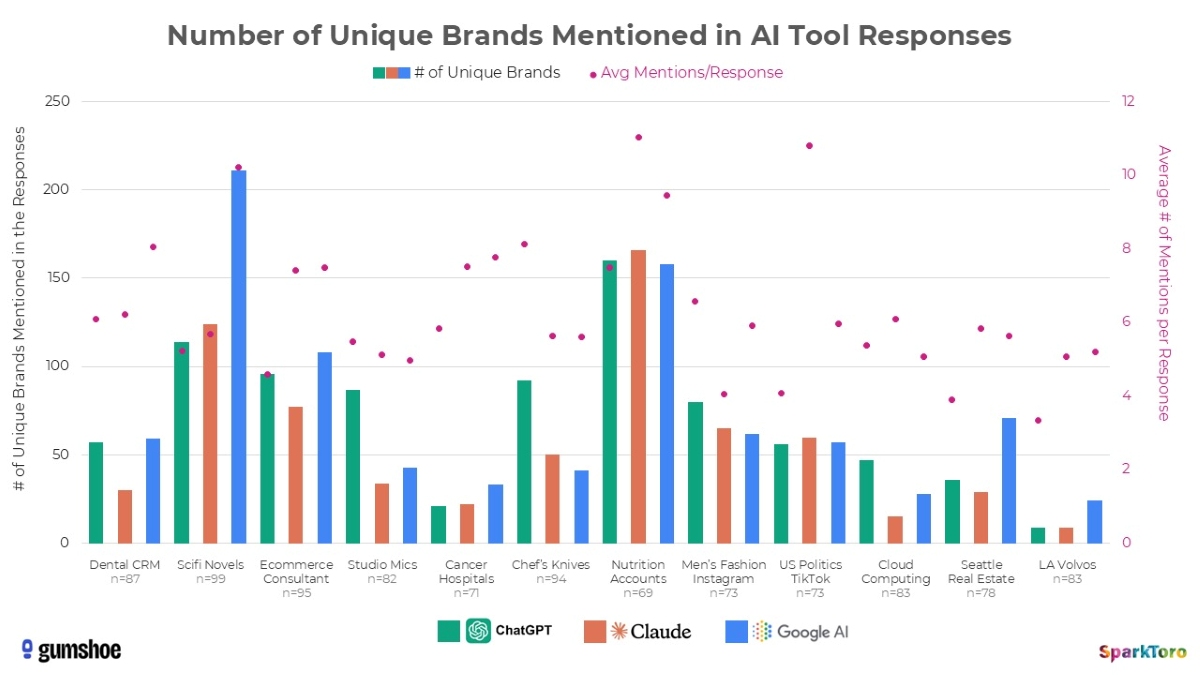
600 volontaires ont été mobilisés. Ils ont exécuté 12 prompts différents couvrant plusieurs secteurs, à la fois grand public et B2B, certains très restreints, d’autres beaucoup plus larges. Chaque prompt a été lancé entre 60 et 100 fois, pour un total de 2 961 réponses collectées.
Les réponses ont ensuite été normalisées afin d’extraire les marques ou produits recommandés, leur ordre d’apparition et le nombre d’éléments proposés à chaque fois. L’objectif était de mesurer trois éléments :
- La stabilité des listes.
- La stabilité de leur classement.
- La fréquence d’apparition des différentes marques.
Dans un second temps, l’étude a intégré des prompts rédigés librement par des utilisateurs autour d’une même intention. Malgré la diversité des formulations humaines, les IA renvoient-elles vers les mêmes marques ?
Des recommandations très variables
« Si vous demandez une centaine de fois à un outil d’IA des recommandations de marques/produits, presque chaque réponse sera unique de trois manières : la liste présentée, l’ordre des recommandations et le nombre d’éléments sur cette liste », affirme d’emblée Rand Fishkin. À cet égard, le graphique ci-dessous est plutôt éloquent. Avec ChatGPT, lorsqu’on effectue 100 fois la même requête, les chances d’obtenir la même liste de marques sont de 0,74 %, les chances d’obtenir les mêmes marques dans le même ordre sont de 0,1 %.
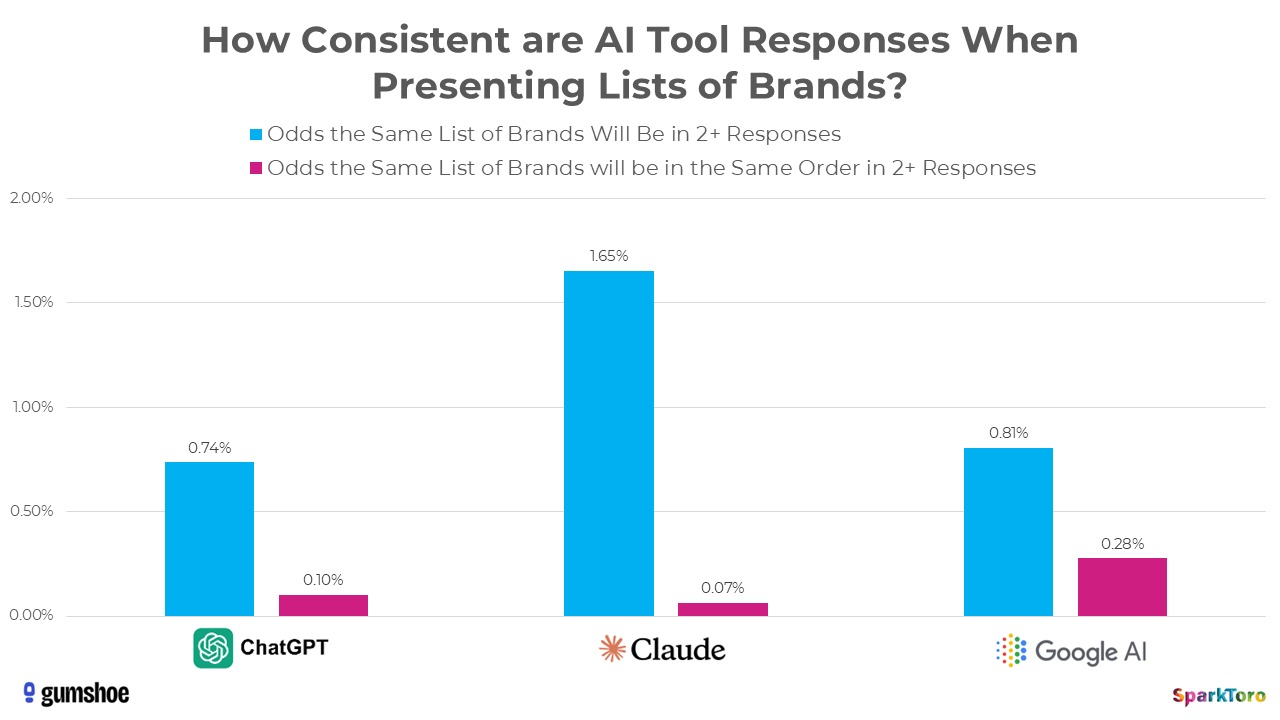
La constance des IA est donc presque nulle. L’auteur précise par ailleurs que les chiffres ne prennent pas en compte le sentiment associé à la marque dans les réponses des IA. Ce sentiment peut, en effet, se doter d’une teinte tantôt positive, tantôt négative selon la réponsé générée.
En résumé : les IA ne fournissent pas de listes cohérentes de recommandations de marques ou de produits. Si une réponse ne vous convient pas, ou si votre marque n’apparaît pas à l’endroit souhaité, n’hésitez pas à réessayer, commente Rand Frishkin, un brin malicieux.
Pour Rand Fishkin, ce phénomène pose un problème de confiance. Sur le traitement d’informations factuelles, les IA affichent des taux de fiabilité supérieurs à 90 % dans certaines études. « Je suis certain que des millions de personnes accordent la même confiance aux IA en matière de recommandations de produits, ignorant tout du processus de l’IA et de ses éventuelles incohérences », poursuit-il. Une tendance relativement indolore s’il s’agit de faire l’acquisition d’une machine à café, mais bien plus problématique si les questions relèvent de problèmes vitaux.
Imaginons un scénario terrible où il est absolument crucial d’obtenir les meilleures informations possibles : un cancer dans la famille. Vous vous précipitez sur le mode IA de Google et demandez quel est le meilleur centre de cancérologie de la côte ouest américaine […] Mais lorsque Google renvoie une réponse, la liste est tellement aléatoire que même si vous exécutiez la requête des centaines de fois, vous ne verriez probablement jamais deux fois la même liste, dans le même ordre.
Ce qui reste mesurable : la visibilité plutôt que la position
Des listes trop différentes entre elles, le GEO à la poubelle ? Pas nécessairement, pour Rand Fishkin. « Mon hypothèse initiale selon laquelle les listes de réponses des marques générées par l’IA sont tellement aléatoires que leur suivi est totalement inutile était fausse », explique-t-il. Ce qui change la donne, selon lui, n’est pas la position d’une marque, mais sa fréquence d’apparition. En effet, même si les classements changent presque entre chaque génération, il semble exister certains ensembles de marques que « les systèmes d’IA associent davantage comme une bonne réponse à l’intention de la requête ».
Par exemple, lorsque l’IA de Google a été invitée à recommander des consultants en marketing digital spécialisés dans le e-commerce, l’agence Smartsites est apparue dans 85 des 95 réponses. C’est significatif.
Une forte visibilité ne garantit d’ailleurs pas un positionnement préférentiel. Elle reflète surtout la place qu’occupe une marque dans l’univers de références du modèle. Dans le cas des hôpitaux spécialisés en cancérologie sur la côte ouest américaine, City of Hope apparaît par exemple dans 97 % des réponses de ChatGPT, mais n’est citée en première position que dans une minorité de cas.
Les limites structurelles : diversité des prompts et effet de la taille du marché
Le SEO consiste, en partie, à suivre le positionnement de vos pages sur certains mots clés ciblés. Pour identifier les bons mots clés, il suffit de comparer les volumes de recherches entre différentes options pour comprendre ce que les utilisateurs écrivent dans la barre de recherche Google. Mais comment faire lorsque les requêtes sont conversationnelles ? Cette problématique constitue un obstacle central, pour Rand Fishkin.
Les suggestions synthétiques sont-elles un bon indicateur de ce que les gens saisissent réellement dans les outils d’IA ? Et quelle est la diversité des suggestions utilisées ? Si vous vous posez ces questions, bravo !, vous êtes bien plus avancés que les milliers d’entreprises qui investissent des millions dans les outils de suivi par IA, souligne Rand Frishkin, tranchant.
Pour prendre en compte cette variable, l’auteur a donc demandé aux répondants de son étude de rédiger le prompt à leur manière. Avec des résultats, à nouveau, significatifs : « Sur 142 réponses, à peine deux suggestions se ressemblaient, même de loin. J’en ai déduit que les suggestions de l’IA sont très différentes d’une recherche Google. Les gens ne se contentent pas de quelques mots-clés parmi les plus logiques ; ils font preuve de créativité, d’originalité et de précision. » En utilisant la méthodologie de Carnegie Mellon, Rand Fishkin constate en effet une très faible similarité sémantique entre les prompts.
Et pourtant, malgré la diversité des formulations, certaines marques apparaissent dans 55 à 77 % des réponses. Ainsi, même si les prompts sont très différents sur le plan linguistique, l’IA parvient à capter l’intention sous-jacente et converge vers un noyau relativement stable de marques.
Les meilleurs générateurs de texte par IA
ChatGPT
Claude
NotebookLM





