Anonymiser les données, une fausse bonne idée pour protéger l’identité des individus
Anonymiser les données ne suffit pas : il est souvent possible de « remonter » jusqu’aux personnes concernées.


L’anonymisation des données ne protège pas vraiment l’identité
Très régulièrement, vous utilisez des services proposant de « transmettre des données anonymisées » – à des fins de recherche produit notamment. C’est même parfois activé par défaut, regardez par vous-même dans les paramètres de vos applications préférées. Quand le consentement de l’utilisateur est questionné (ce qui ne semble pas obligatoire, pour des données anonymes, au regard des lois en vigueur), celui-ci est souvent enclin à accepter. L’anonymisation des données le rassure, il estime qu’il ne prend aucun risque en transmettant ses données car rien ne permettra de « remonter » jusqu’à lui. C’est être bien naïf que de penser ainsi : les résultats d’une étude, réalisée par des chercheurs de l’Université catholique de Louvain et l’Imperial College de Londres, montrent qu’il n’est pas si compliqué de relier des personnes à des données dites « anonymisées ».
99,98% des Américains identifiés malgré l’anonymisation des données
Les chercheurs ont tenté de retrouver les personnes à qui appartenaient des données anonymes. Ils sont arrivés à la conclusion qu’avec 15 données démographiques (ce qui est à la fois beaucoup, mais également peu au vu des traces laissées en ligne…) leur modèle était en mesure d’identifier correctement un Américain dans 99,98% des cas. La combinaison de ces 15 données est pratiquement toujours unique, ce qui permet de retrouver facilement l’individu correspondant à ces données.
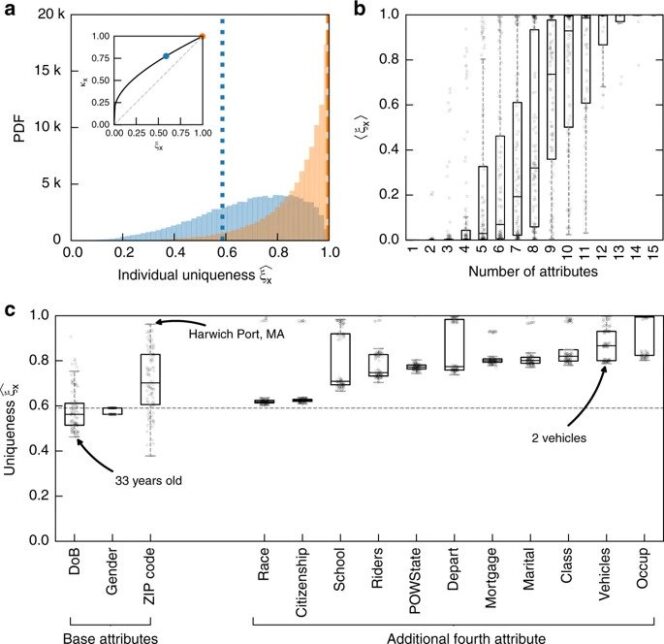
L’étude menée par les chercheurs se place dans le contexte des changements récents de législation ; notamment le RGPD pour les Européens et le California Consumer Privacy Act, le CCPA, en Californie. Ces textes précisent que l’identité d’un individu présent dans un dataset doit être protégée pour que cet ensemble de données soit considéré comme anonymisé. Lorsqu’un ensemble de données est considéré comme anonymisé, on estime que les données qui y sont stockées ne sont plus des données personnelles. La législation devient alors beaucoup plus souple et les propriétaires peuvent échanger ou vendre leurs fichiers très facilement, sans trop craindre d’actions légales.
Hors, plusieurs exemples récents montrent qu’il est possible de retrouver les personnes concernées en croisant des fichiers. Les chercheurs souhaitaient vérifier à quel point il était aisé de retrouver une personne via ces données considérées comme anonymes. Conclusion : avec quelques données et un modèle éprouvé, on arrive donc à identifier une personne dans près de 100% des cas. Les citoyens américains et anglais peuvent même tester la fiabilité du modèle par eux-mêmes…
Des organisations peuvent donc, techniquement, effectuer des croisements pour associer des informations à chaque individu : agences gouvernementales, entreprises qui souhaitent mesurer précisément les risques qu’elles encourent avant de signer un contrat avec un individu…. Pensez-y la prochaine fois que vous acceptez un traitement, voire un transfert, de vos données soit disant anonymes.


La boîte à questions sur l'IA générative
Outils, prompts, usages professionnels, comparatifs... Posez toutes vos questions à Ludovic Salenne, expert IA !
Je pose une questionLes meilleurs outils pour les professionnels du web
Obat
Qonto
jeboostemaboite






Attention, l’article confond le principe de pseudonymisation et d’anonymisation tel que défini par la CNIL. Cette dernière ne considère des données comme anonymisées uniquement si elle résistent aux trois critères que sont la l’individualisation, la corrélation, et l’inférence