Common Voice et Deep Speech : les projets de Mozilla pour développer des solutions de reconnaissance vocale
Google, Alexa, Siri… Les assistants vocaux des plus grandes entreprises de la tech se positionnent comme les ambassadeurs du marché. Dans une telle configuration, il est difficile pour tout nouvel acteur de trouver sa place. Sauf si ce dernier s’engage à un traitement plus éthique de la voix, des données collectées et se donne pour mission de favoriser l’accessibilité. C’est ce que propose Mozilla, avec son projet Common Voice et sa technologie Deep Speech. La firme a l’ambition d’offrir une solution ouverte et moins coûteuse à tous ceux qui souhaitent développer des produits de reconnaissance vocale. En marge de la Digital Tech Conference de ce 30 novembre à Rennes, nous avons interrogé Kelly Davis, chercheur en machine learning chez Mozilla, pour en savoir plus sur les projet du groupe.
Pouvez-vous nous expliquer les projets de Deep Speech et Common Voice et Mozilla ? Quels sont les enjeux et les objectifs ?

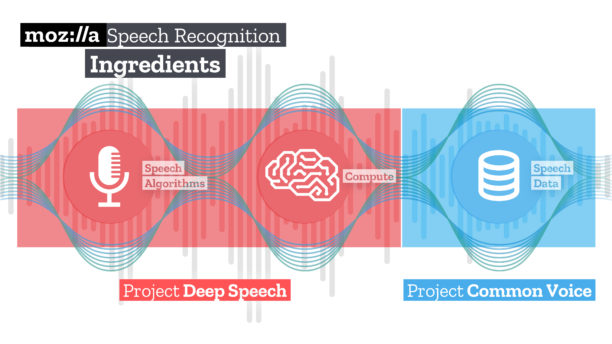
La technologie de reconnaissance vocale révolutionne la manière dont nous interagissons avec les machines. Mais pour le moment, l’accès à cette technologie est coûteux et ne comprend pas un ensemble diversifié d’accents et de langues. Seule une poignée d’entreprises contrôle l’accès à toutes les fonctions de reconnaissance vocale. Deep Speech et Common Voice sont deux projets complémentaires par lesquels Mozilla souhaite modifier cet état de fait.
Deep Speech, d’une part, offre un logiciel de reconnaissance vocale ouvert à tous et dans toutes les langues. Mozilla utilise du code source ouvert, des algorithmes et la boîte à outils d’apprentissage automatique TensorFlow pour créer son moteur de synthèse vocale (STT). L’architecture de deep learning de Mozilla sera disponible pour tous, en tant que technologie de base pour les nouvelles applications vocales. Nous prévoyons de créer et de partager des modèles susceptibles d’améliorer la précision de la reconnaissance vocale et de produire une synthèse vocale de haute qualité.
Lorsque les utilisateurs parlent à Alexa, Siri ou Google, les interactions sont consignées et les données vocales restent la propriété de ces entreprises. On se retrouve alors dans une situation déséquilibrée, où toute personne souhaitant développer des appareils de haute qualité, dotés de la reconnaissance vocale, doit utiliser l’un des rares services offerts par les grandes entreprises. Cela ralentit l’innovation.
Common Voice vise à changer cette situation en créant une base de données de fichiers audio, ouverte et accessible au public, que tout le monde peut utiliser pour former de nouvelles applications vocales et permettant à chacun d’innover et d’améliorer l’expérience vocale pour tous.
Quelle place prennent ces projets dans l’écosystème Mozilla ?
Common Voice est un projet d’Open Innovation qui dépasse Mozilla. Nous voulons rendre cet ensemble de données vocales multilingues aussi utile que possible pour tous, y compris les chercheurs, les universités, les startups, les gouvernements, les organisations à vocation sociale et les amateurs. Notre objectif est de générer le maximum d’innovations à l’aide de ces données, qui seront libres de droit. Cela signifie que la personne qui utilise les données vocales n’a pas besoin d’être autorisée par Mozilla, et il n’y aura pas de restrictions d’utilisation. Bien sûr, nous l’utilisons pour former le projet DeepSpeech, notre propre moteur de reconnaissance vocale open source.
Quelle analyse faites-vous de l’importance croissante des assistants vocaux dans le quotidien des utilisateurs ?
La parole devient un moyen privilégié d’interagir avec les appareils électroniques personnels tels que les téléphones, les ordinateurs, les tablettes et les téléviseurs. Quiconque a déjà dû saisir un titre de film à l’aide de la télécommande de son téléviseur peut témoigner de la commodité d’une interface vocale. Selon une étude, il est trois fois plus rapide de communiquer avec votre téléphone ou votre ordinateur que de saisir une requête de recherche dans une interface à écran.
De plus, le nombre d’appareils vocaux augmente chaque jour à mesure que les assistants vocaux gagnent en popularité sur le marché. Les interfaces vocales sont donc pratiques – et deviennent rapidement omniprésentes. Mais au-delà d’être une « technologie pratique » pour nous, réfléchissez à la manière dont les locuteurs d’une langue minoritaire pourraient utiliser la reconnaissance vocale pour permettre à davantage de personnes d’avoir accès à la technologie et aux services Internet, même s’ils n’ont jamais appris à lire ? Il en va de même pour les personnes malvoyantes ou ayant un handicap physique (c’est-à-dire les personnes ne pouvant utiliser un écran tactile ou un clavier). Les forces régulières du marché n’aideront pas ces gens. C’est l’une des raisons pour lesquelles nous avons lancé le projet Common Voice.
Quels sont selon vous les opportunités et les obstacles de cette tendance ?
Les opportunités sont immenses. La démocratisation de la technologie vocale ne réduira pas seulement la barrière de l’innovation mondiale, mais également la barrière de l’accès à l’information. Cela est particulièrement vrai pour les personnes qui ont traditionnellement eu moins de cet accès – par exemple, les malvoyants, les personnes qui n’ont jamais appris à lire, les enfants, les personnes âgées et bien d’autres.
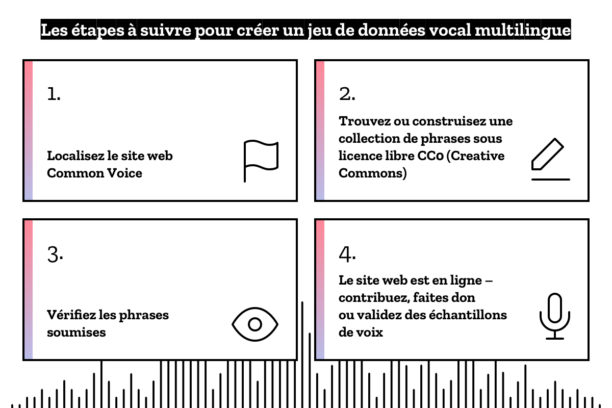
Toutefois, la collecte de données pour former ces technologies peut constituer un obstacle important. Il faut des milliers d’heures de transcription, provenant de milliers de locuteurs dans une langue cible et, idéalement, des données qui devraient être conversationnelles, reflétant la façon dont on parle à un ami ou à une connaissance. L’obtention de telles données est coûteuse et prend du temps, ce qui est presque impossible pour les petites entreprises, les startups, les universités, etc. Mozilla s’est donc lancé dans la mêlée avec Common Voice, un projet qui collecte et exploite de manière ouverte ces données.
Qu’en est-il de la protection des données des utilisateurs ? Quelles sont les actions de Mozilla sur cette question ?
Aujourd’hui, la majorité des moteurs de reconnaissance vocale actuels nécessitent une connexion Internet. Votre voix est envoyée depuis votre téléphone, votre ordinateur, votre tablette ou votre télévision vers des serveurs qui convertissent votre discours en texte. Il est évident que l’envoi de votre voix sur des serveurs soulève un certain nombre de problèmes de sécurité et de confidentialité.
Nous nous efforçons de faire de Common Voice la référence absolue en matière de portabilité et de confidentialité des données. Nous avons travaillé avec des régulateurs et d’autres sociétés de l’UE et des États-Unis axées sur la protection de la vie privée pour aller au-delà des exigences (telles que le RGPD), tout en maintenant les enregistrements aussi utilisables que possible. Nous veillons à ce que les personnes qui font don de leurs enregistrements vocaux conservent toujours le contrôle de leurs propres données, y compris le nombre d’informations d’identification personnelles qu’ils incluent.
À ce titre, les versions de Deep Speech permettront également d’effectuer une reconnaissance vocale embarquée, c’est-à-dire sur l’appareil même, évitant ainsi tous ces problèmes de sécurité et de confidentialité.
Les meilleurs outils pour les professionnels du web
2Be-FFICIENT
CentralPay
Dexem Call Tracking